Overview
This guide will help you migrate your existing pipelines from the deprecated Tool node to the Toolkit node.Why Was the Tool Node Deprecated?
The Tool node has been replaced by the more capable Toolkit node, which provides:- Broader functionality: Support for all toolkit types and capabilities
- Enhanced filtering: Better control over which tools are available
- Structured outputs: Built-in support for structured output handling
- Clearer purpose: More intuitive naming and functionality
Understanding Tool Node Functionality
The Tool node was essentially a toolkit with an integrated LLM layer. This meant the LLM automatically handled parameter mapping tasks that you would otherwise need to configure manually.Our design philosophy prioritizes using LLM nodes only when necessary. Non-LLM approaches offer better consistency, faster execution, and token efficiency. Use LLM-based solutions when you need dynamic parameter interpretation or natural language processing capabilities.
Migration Alternatives
You have two migration strategies depending on your use case:Option 1: LLM Node with Toolkit (Tool Node Equivalent)
This approach most closely replicates the original Tool node functionality. When to use:- You need dynamic parameter mapping based on context
- Input configurations vary significantly between executions
- Natural language interpretation is required
- You want LLM to handle the parameter mapping logic
- Add an LLM node to your pipeline
- Attach the corresponding toolkit to the LLM node
- The LLM handles parameter mapping automatically (similar to the original Tool node)
- ✔️ Flexible and context-aware
- ✔️ Handles variable input structures
- ✘ Slower execution due to LLM processing
- ✘ Consumes tokens (cost implications)
- ✘ Less predictable outputs
Option 2: Non-LLM Nodes (Recommended for Data Management)
This approach uses deterministic nodes without LLM involvement. When to use:- Input configurations remain consistent
- You need predictable, repeatable results
- Speed and token efficiency are priorities
- You have technical resources for initial setup
- Toolkit node: Execute toolkit functions with explicit parameter mapping
- State Modifier node: Use Jinja2 templating to transform state values (e.g., extract values from JSON)
- Code node: Execute Python code with access to pipeline state and artifacts
- ✔️ Consistent and predictable results
- ✔️ Faster execution
- ✔️ Token-efficient (no LLM costs)
- ✘ Requires setup and testing
- ✘ Requires technical mindset
- ✘ Less flexible with varying input structures
- Use Toolkit node to read files and save content in pipeline state
- Use State Modifier node with Jinja2 templating to extract or transform values from JSON
- Use Code node to perform complex data processing with Python
Migration Path
There is no automatic migration for Tool nodes. You must manually replace existing Tool nodes with Toolkit nodes in your pipelines.What You Need to Know
- Manual migration required: Each Tool node must be replaced manually
- Configuration transfer: You’ll need to reconfigure toolkit selections and settings
- No data loss: Your existing pipelines with Tool nodes will continue to work
- Future-proofing: Migrating now ensures compatibility with future releases
Step-by-Step Migration: Tool Node to Toolkit Node
This guide walks you through migrating a Tool node to a Toolkit node using a Confluence toolkit as a practical example.Step 1: Identify Tool Nodes in Your Pipeline
- Open your pipeline in the Flow Editor
- Look for nodes labeled as “Tool” (they may be marked as deprecated)
- Note the toolkit and configuration for each Tool node
- Node Type: Tool (deprecated)
- Toolkit Selected: Confluence
- Tool: read_page_by_id
- Task: “Read Confluence page with id=” (Tool node specific field)
- Inputs: page_id
- Outputs: page_content
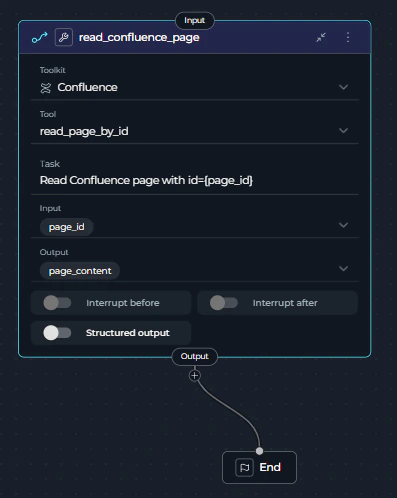
Step 2: Add a Toolkit Node
- Click + Add Node in the Flow Editor
- Select Toolkit from the available node types
- Place the new Toolkit node near the Tool node you’re replacing
read_confluence_page node in the Flow Editor.
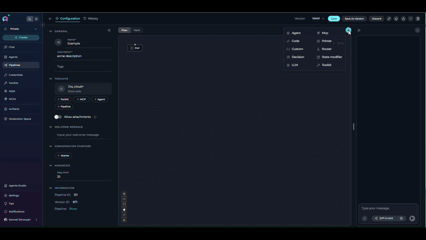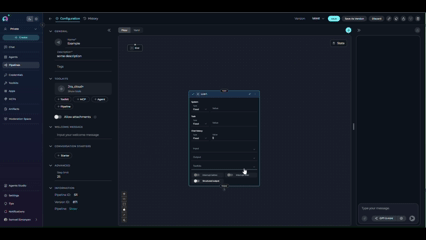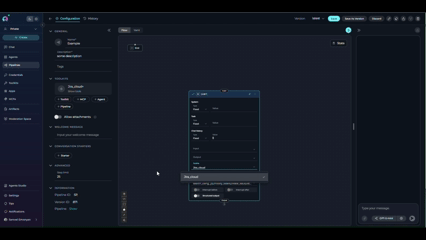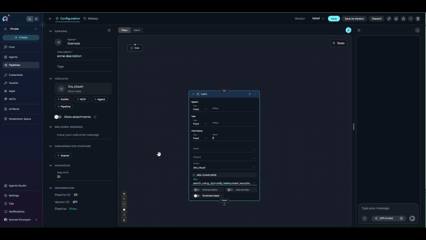
Step 3: Configure the Toolkit Node
-
Select the toolkit:
- Open the Toolkit node settings
- Choose the same toolkit that was configured in your Tool node
- The toolkit filter automatically excludes application-type tools
-
Set up input mappings:
- Transfer the same input mappings from your Tool node
- Ensure variable names and sources match exactly
-
Set up structured output (if needed):
- The Toolkit node includes structured output support
- Configure output schema if your workflow requires structured data
- Task field removed: The Toolkit node doesn’t have a
taskfield - Tool field kept: The
toolfield is explicitly specified (e.g.,read_page_by_id) - Input mapping added: The Toolkit node uses
input_mappingto configure tool parameters:page_id: Can usefstringtype to format the page ID (e.g.,'page id:{page_id}')skip_images: Boolean flag to skip image processing (set tofalseto include images)- Each mapping has a
type(fixed,fstring,from_state, etc.) and avalue
Step 4: Reconnect Edges
-
Disconnect the Tool node:
- Remove incoming edges to the Tool node
- Remove outgoing edges from the Tool node
-
Connect the Toolkit node:
- Connect the same incoming edges to the Toolkit node
- Connect the same outgoing edges from the Toolkit node
- Verify the data flow matches your original pipeline
Step 5: Update Variable Mappings
-
Check input mappings:
- Verify that variables passed to the Tool node are now mapped to the Toolkit node
- Update any variable references if node IDs have changed
-
Check output mappings:
- Update any downstream nodes that reference the Tool node’s output
- Change references to point to the Toolkit node’s output instead
Step 6: Remove the Old Tool Node
- Select the deprecated Tool node
- Delete the node from your pipeline
- Verify that no broken edges or references remain
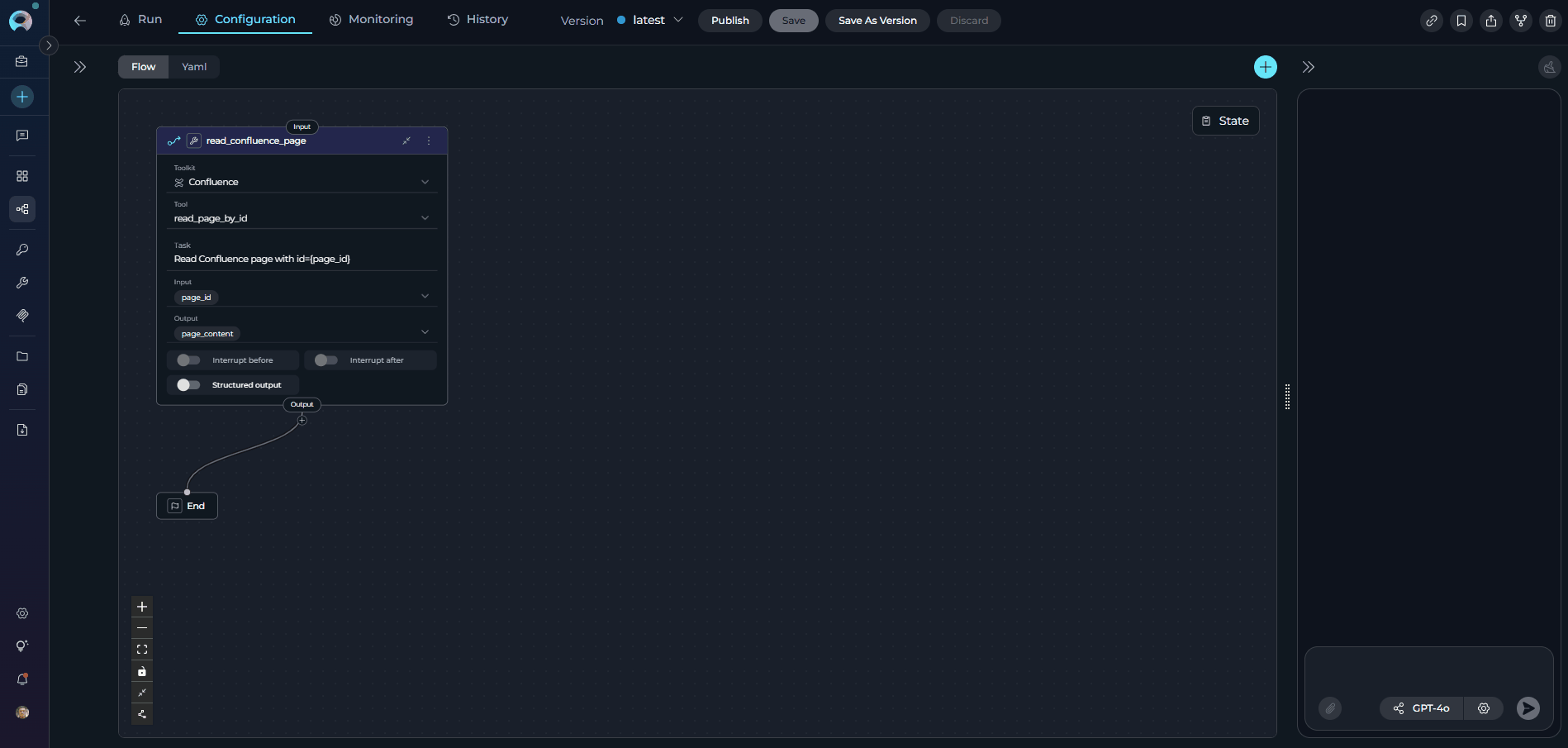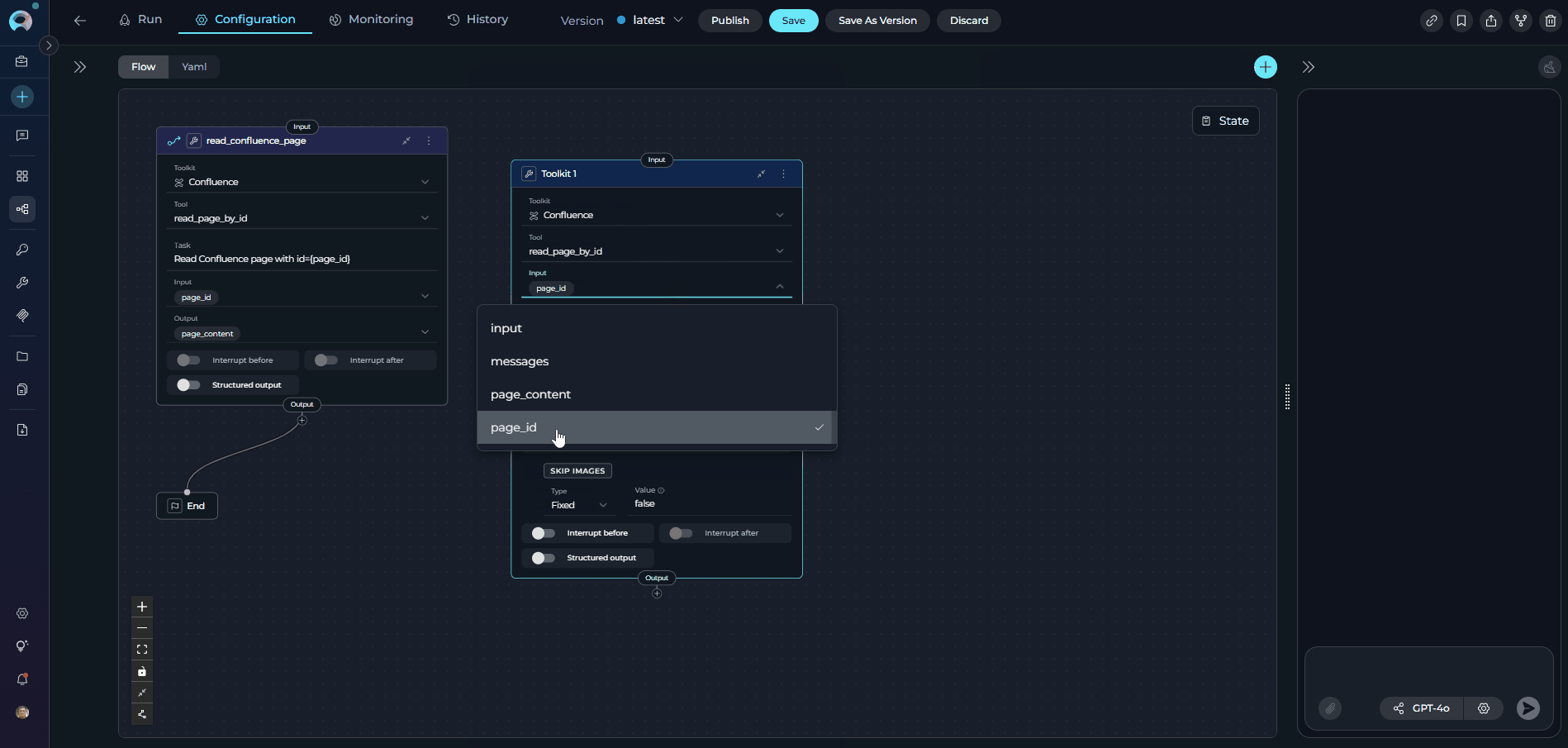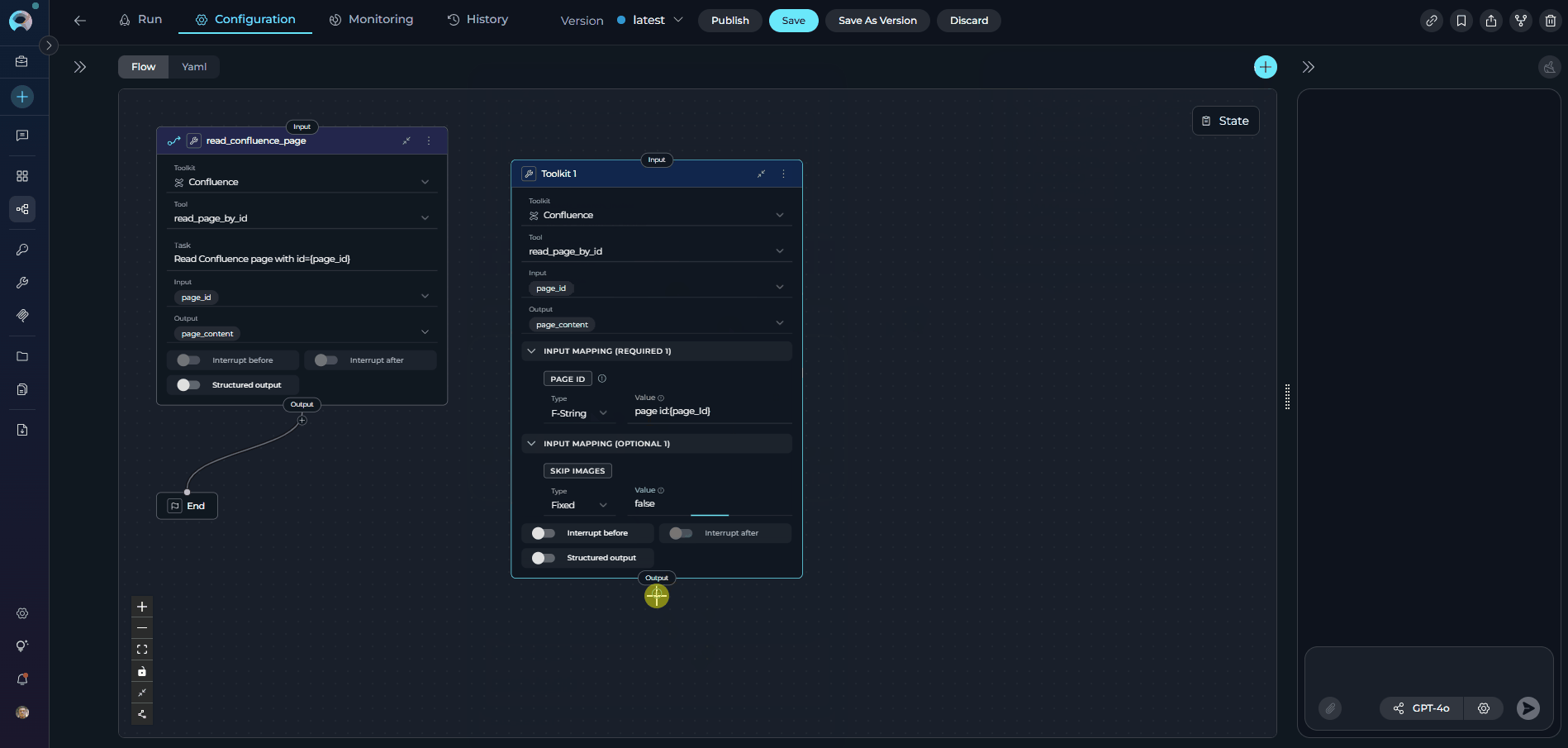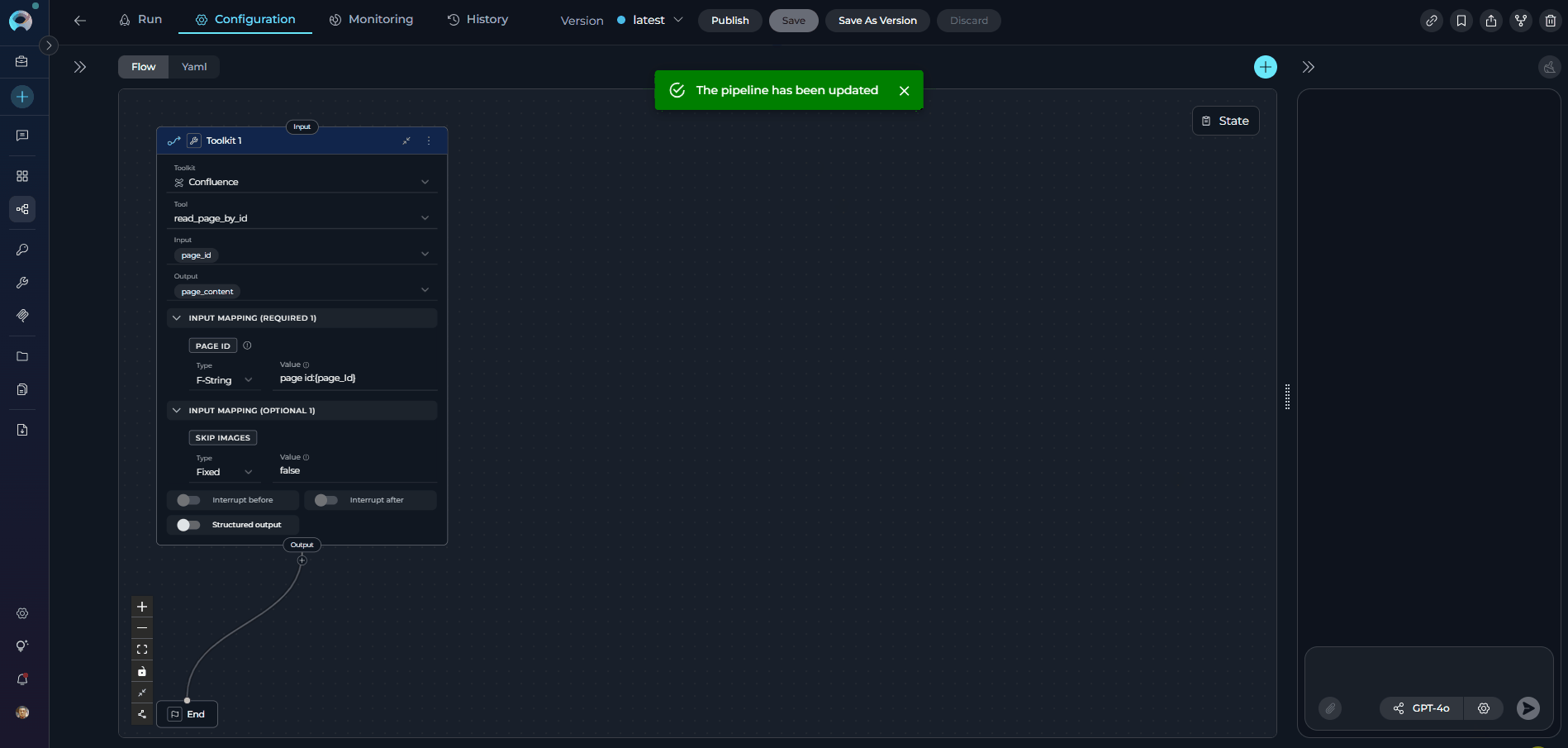
- Node Type: Toolkit (current)
- Toolkit Selected: Confluence (same toolkit)
- Tool: read_page_by_id (now explicitly specified)
- Inputs: page_id (same as Tool node)
- Input Mapping: Maps page_id using fstring format and sets skip_images to false
- Outputs: page_content (same as Tool node)
Step 7: Test Your Pipeline
- Save your changes
- Run the pipeline to ensure the Toolkit node functions as expected
- Verify outputs match the behavior of the original Tool node
- Check error handling and edge cases
- The Confluence page is retrieved successfully using the
read_page_by_idtool - The page content for page ID
123456is correctly returned - The output in
page_contentcontains the complete page content - Downstream nodes receive the expected output
Migration Summary
What Stays the Same:- ✔️ Toolkit selection
- ✔️ Input/output configuration
- ✔️ Functionality and behavior
- ✔️ Structured output setting
- ✘ Node type (tool → toolkit)
- ✘ Node ID (read_confluence_page remains the same)
- ✘ Task field removed (Toolkit node doesn’t have this field)
- ✔️ Tool field kept
Troubleshooting
Toolkit Not Showing in Dropdown
Problem: The toolkit you were using in the Tool node doesn’t appear in the Toolkit node. Solution:- Verify the toolkit type is not an application-type tool
- Check that the toolkit still exists in your workspace
Pipeline Execution Fails After Migration
Problem: Pipeline runs successfully with Tool node but fails with Toolkit node. Solution:- Verify all variable mappings are correctly updated
- Check that input/output connections match the original configuration
- Ensure the toolkit name and configuration are identical
- Review any structured output schemas that may need adjustment
Output Format Changed
Problem: The output format from the Toolkit node differs from the Tool node. Solution:- Check if structured output is enabled in the Toolkit node
- Review the toolkit’s output schema configuration
- Adjust downstream nodes to handle the new output format
- Consider using the structured output feature for better data handling
Input Mapping Configuration Issues
Problem: Errors related to input_mapping configuration or variable types. Solution:-
Understand mapping types: The Toolkit node uses different type values in
input_mapping:Fixed: Static value that doesn’t change (e.g.,value: falsefor boolean flags)F-String: Format string with variable substitution (e.g.,value: 'page id:{page_id}')Variable: Reference a variable from the pipeline state (e.g.,value: 'page_id')
-
Check variable syntax: Ensure variables use correct syntax:
- In
F-Stringtype:'text {variable_name}'(curly braces for substitution) - In
Variabletype:'{variable_name}'(reference state variable)
- In
-
Verify mapping structure: Each input_mapping entry needs both
typeandvaluefields - Match tool requirements: Check the tool’s documentation for required parameters and their expected formats
- YAML Configuration - Complete YAML syntax and structure
- Pipeline States - Working with state variables
- Pipeline Overview - Understanding pipeline concepts
- Nodes and Connectors - Node types and connections
- Flow Editor Guide - Visual pipeline editing
- Execution Nodes - Toolkit and other execution nodes
Frequently Asked Questions
How do I get data from toolkit and save it in states?
Problem: The Tool node allowed reading data from different external sources (e.g., JSON files stored in Artifacts) and using those values directly in parameters. With Toolkit nodes, you need to explicitly set parameter values instead of referencing artifact content. Example scenario:- You have a JSON stored in Artifacts
- You use included pipelines with hierarchical architecture
- Previously, the Tool node could read from artifacts and get values automatically
- Read the JSON file: Use a Toolkit node to read the JSON artifact and save it to pipeline state
- Parse and extract values: Use a State Modifier node with Jinja2 templating to extract specific values
- Use extracted values: Reference the extracted state variables in downstream Toolkit nodes
- Attach the toolkit to an LLM node
- The LLM will handle dynamic parameter mapping from your configuration
- This approach is less efficient but more flexible
Which migration approach should I choose?
Choose LLM Node + Toolkit if:- You need the LLM to interpret or map parameters dynamically
- Your input data structure varies between executions
- You’re prototyping and need quick setup
- Natural language processing is part of your workflow
- Your input configuration structure is consistent
- You need maximum speed and reliability
- Token efficiency is important (cost reduction)
- You have technical resources for setup and testing
- You’re building production pipelines with data management
How do I choose between State Modifier and Code node?
Use State Modifier when:- You need simple value extraction from JSON
- String formatting or concatenation is required
- Jinja2 templating can handle your transformation logic
- You want declarative, configuration-based transformations
- You need complex data processing logic
- Multiple conditional branches are required
- You need to access external libraries
- You require programmatic control over artifacts and state
Where can I learn more about the alternative nodes?
- LLM Node: LLM Node Documentation
- Toolkit Node: Toolkit Node Documentation
- State Modifier Node: State Modifier Node Documentation
- Code Node: Code Node Documentation
- Agent Node: Agent Node Documentation
- All Node Types: Nodes Overview
- Pipeline States: Working with Pipeline States
- YAML Configuration: YAML Configuration Guide