- LLM Node - Directly interact with Large Language Models
- Agent Node - Delegate tasks to pre-configured AI agents
LLM Node
The LLM Node provides direct access to Large Language Models (GPT-4, Claude, etc.) for text generation, analysis, extraction, and decision-making. It’s the most versatile interaction node, supporting chat history, tool calling, and structured output extraction.If you have existing pipelines with old LLM node format, see the v2.0.0 Migration Guide for updating to the new System/Task structure.
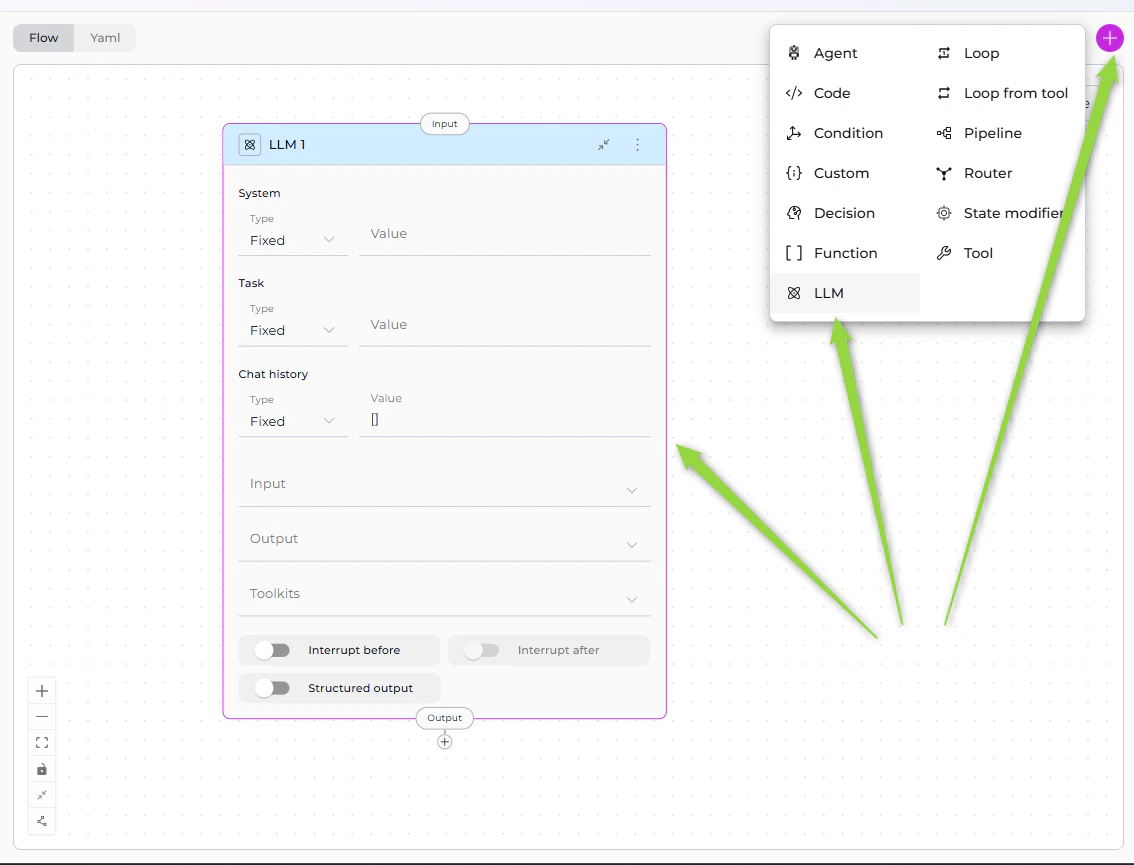
Purpose
Use the LLM Node to:- Generate text based on prompts and context
- Analyze content and extract insights
- Extract structured data from unstructured text
- Have conversations with full chat history support
- Call tools via function calling
- Make intelligent decisions based on context
Parameters
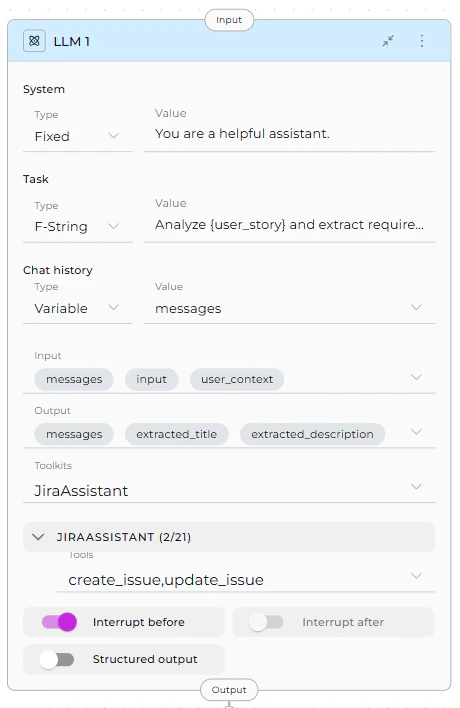
- Select Toolkit/MCP from dropdown
- Tool dropdown appears for that toolkit
- Select specific tools to make available to the LLM
- Repeat for multiple toolkits (each gets its own tool dropdown)
Best Practices
1. Always Include messages in Output for Interrupts
When using structured output with interrupts:
✅ Correct:
2. Use Appropriate Prompt Types
- Fixed: For static, unchanging instructions
- F-String: When you need to inject specific state variables
- Variable: When the entire prompt comes from state
3. Limit Tool Binding
Only bind tools the LLM actually needs: ✅ Good: Select specific relevant tools4. Structure Your Prompts
Use clear, structured prompts: ✅ Good:5. Specify Output Variables Clearly
Match output variables to what you’re extracting: ✅ Good:6. Use Chat History Wisely
- Include
messagesin input when context matters - Use
[](empty array) for stateless single-turn requests
7. Test with Interrupts
Use interrupts during development to verify LLM outputs:8. Handle Tool Calling Errors
When using toolkits, account for potential tool failures in your prompt:Agent Node
The Agent Node allows you to delegate tasks to pre-configured AI agents that have been added to your pipeline. Instead of configuring LLM behavior from scratch, you leverage existing agents with specialized capabilities, prompts, and toolkits.
Purpose
Use the Agent Node to:- Delegate complex tasks to specialized agents
- Reuse existing agents across multiple pipelines
- Maintain consistency with pre-configured agent behavior
- Simplify workflows by avoiding duplicate LLM configuration
- Leverage agent-specific toolkits and integrations
Parameters
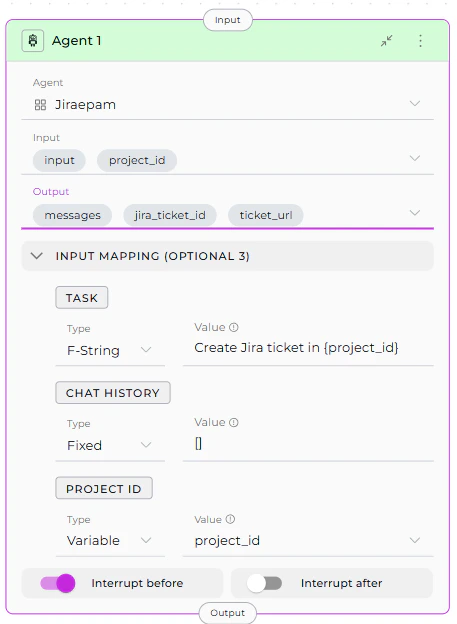
The Input Mapping section appears after you select an agent. Every agent includes TASK and CHAT_HISTORY mappings. If the agent has custom variables, they also appear as mapping options.
Best Practices
1. Add Agents to Pipeline First
Ensure the agent is added in Pipeline Configuration > Toolkits section before using Agent Node.2. Map Task Clearly
Provide clear, specific task instructions: ✅ Good:3. Use Chat History Appropriately
- With History: Use when agent needs conversation context
- Without History: Use
[]for independent, stateless tasks
4. Map Custom Variables Correctly
If agent has custom variables, map them to pipeline state: ✅ Good:5. Include messages in Output
For debugging and continuity, include messages:
6. Use Interrupts for Testing
Test agent behavior with interrupts:7. Reuse Agents Across Pipelines
Create specialized agents once, reuse in multiple pipelines for consistency.8. Handle Agent Failures
Consider error handling in subsequent nodes:Interaction Nodes Comparison
When to Use LLM Node
✅ Choose LLM Node when you need:- Full control over prompts and behavior
- Custom tool binding for specific workflow
- One-off or unique LLM interactions
- Structured output extraction
- Simple text generation without pre-configuration
When to Use Agent Node
✅ Choose Agent Node when you:- Have an existing agent that does exactly what you need
- Want to reuse agent logic across multiple pipelines
- Need consistent behavior from pre-configured agents
- Want to simplify pipeline by delegating to specialists
- Have agents with specific domain knowledge or toolkits
- Nodes Overview - Understand all available node types
- Execution Nodes - Call external tools and execute code
- States - Manage data flow through pipeline state
- Connections - Link nodes together
- YAML Configuration - See complete node syntax examples
- Updating LLM Nodes (v2.0.0 Migration) - Guide for migrating old LLM nodes to new format