In previous releases, there was a Source type: File option in Datasources. Now, Datasources have been removed from ELITEA, and users can perform the same action through SharePoint Toolkit indexing.How to migrate from Datasources to SharePoint Toolkit:
- Add files to SharePoint: Upload your documents to SharePoint document libraries or sites (if not already there)
- Set up credentials: Configure your SharePoint credentials in Settings → Credentials
- Create SharePoint Toolkit: Go to Toolkits → + Create → SharePoint and configure with your site details
- Index your data: Use the “Index Data” tool from the SharePoint Toolkit to create searchable indexes
- Search and chat: Use the toolkit in conversations or agents to query your indexed SharePoint content
Overview
SharePoint indexing allows you to create searchable indexes from your SharePoint document management and collaboration content:- Documents & Files: Word documents, PDFs, Excel spreadsheets, PowerPoint presentations, and other file types
- Document Libraries: Organized collections of documents with metadata and version control
- Lists & Custom Data: Task lists, contact lists, custom data tables, and project tracking information
- Site Collections: Multiple SharePoint sites organized under a shared management structure
- Metadata & Properties: Document properties, custom fields, and content categorization
- Semantic Search: Find documents and content across SharePoint sites using natural language queries
- Context-Aware Chat: Get AI-generated answers from your document content with citations to specific files
- Cross-Site Discovery: Search across multiple SharePoint sites and document libraries
- Document Analysis: Extract insights and summaries from business documents and reports
- Content Organization: Analyze document types, usage patterns, and content relationships
- Finding specific documents, policies, or procedures across your organization’s SharePoint sites
- Onboarding new employees by allowing them to ask questions about company documents and processes
- Analyzing project documents and extracting key information for reporting and decision-making
- Support teams searching for solutions and documentation from indexed knowledge bases
- Compliance and audit teams finding relevant documents based on content and metadata
Prerequisites
Before indexing SharePoint data, ensure you have:- SharePoint Credential: An Azure AD app registration with authentication credentials configured in ELITEA
- Vector Storage: PgVector selected in Settings → AI Configuration
- Embedding Model: Selected in AI Configuration (defaults available) → AI Configuration
- SharePoint Toolkit: Configured with your SharePoint site details and credentials
Required Permissions
Your SharePoint credential needs appropriate permissions based on what you want to index: For Content Access:- Read access to SharePoint sites and document libraries
- Permission to view the specific sites and libraries you want to index
- Access to view document content and metadata
- Permission to access both public and restricted content (based on your requirements)
- Ability to read from multiple document libraries and lists
- Azure AD App Registration: Client ID and Client Secret for application-only access
- Delegated Permissions: For user-context access (alternative approach)
Step-by-Step: Creating a SharePoint Credential
- Register App in Azure AD: Create an Azure AD app registration with appropriate SharePoint permissions
- Generate Client Secret: Create a client secret for secure authentication
- Grant Site Permissions: Use SharePoint’s AppInv.aspx to grant site-level permissions
- Create Credential in ELITEA: Navigate to Credentials → + Create → SharePoint → enter details and save
For complete credential setup steps including Azure AD app registration, permissions, and security best practices, see:
Step-by-Step: Configure SharePoint Toolkit
- Create Toolkit: Navigate to Toolkits → + Create → SharePoint
- Configure Settings: Set SharePoint site URL and assign your SharePoint credential
- Enable Tools: Select
Index Data,List Collections,Search Index,Stepback Search Index,Stepback Summary Index, andRemove Indextools - Save Configuration
Tool Overview:
- Index Data: Creates searchable indexes from SharePoint documents and content
- List Collections: Lists all available collections/indexes to verify what’s been indexed
- Search Index: Performs semantic search across indexed content using natural language queries
- Stepback Search Index: Advanced search that breaks down complex questions into simpler parts for better results
- Stepback Summary Index: Generates summaries and insights from search results across indexed content
- Remove Index: Deletes existing collections/indexes when you need to clean up or start fresh
For complete toolkit configuration including site URL setup and authentication options, see:
Step-by-Step: Index SharePoint Data
Step 1: Open the Indexes Tab- Navigate to Toolkits and select your SharePoint toolkit.
- Click the Indexes tab in the toolkit detail view.
-
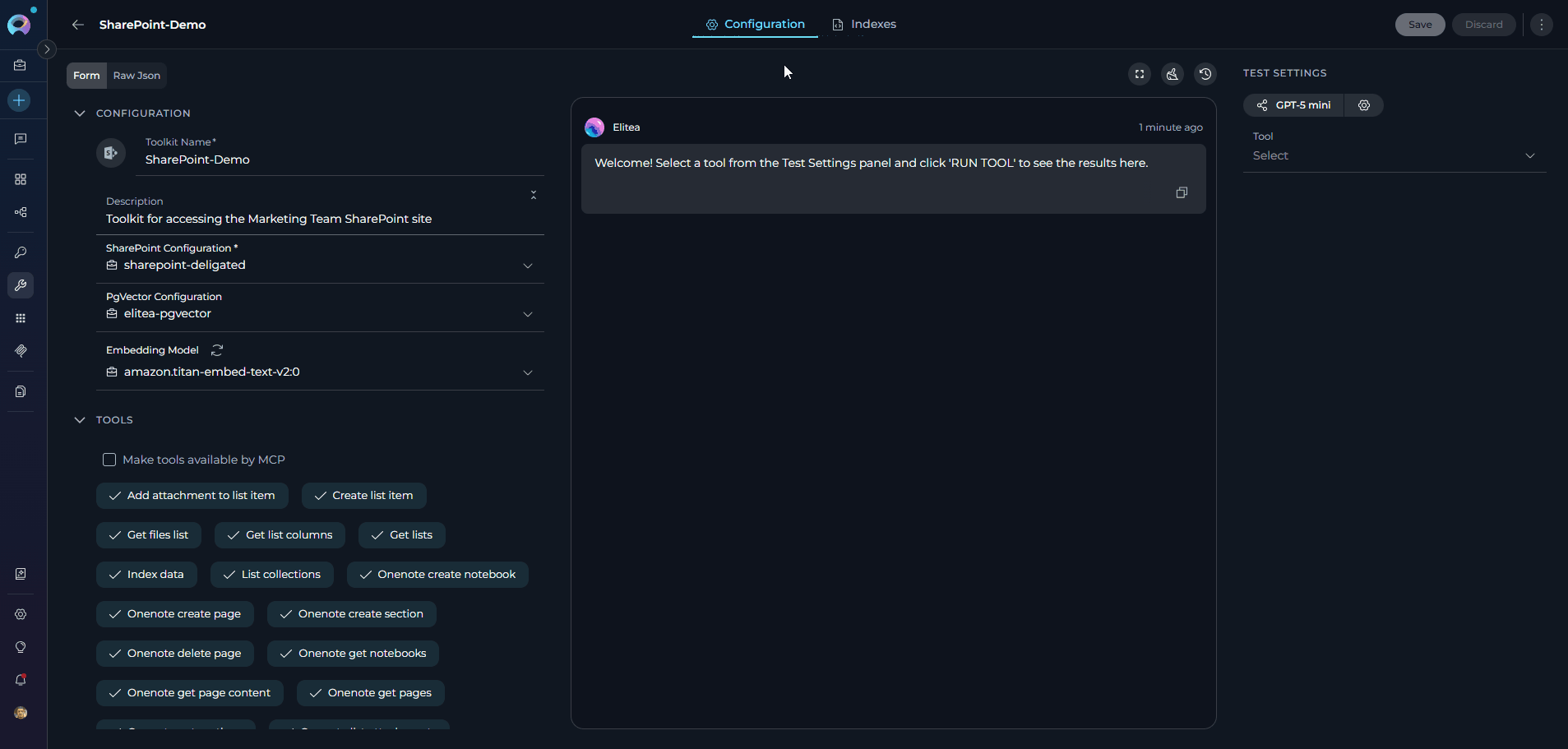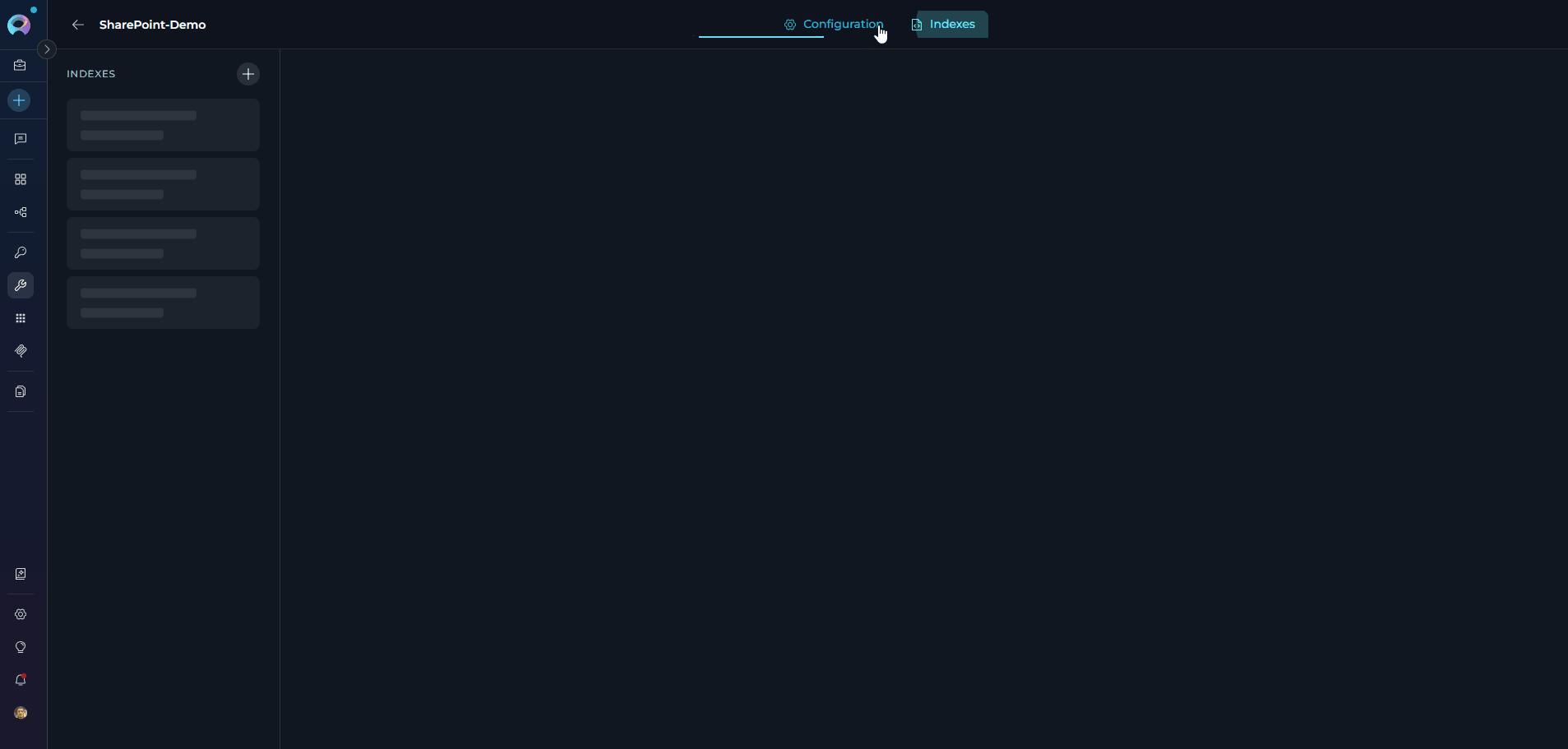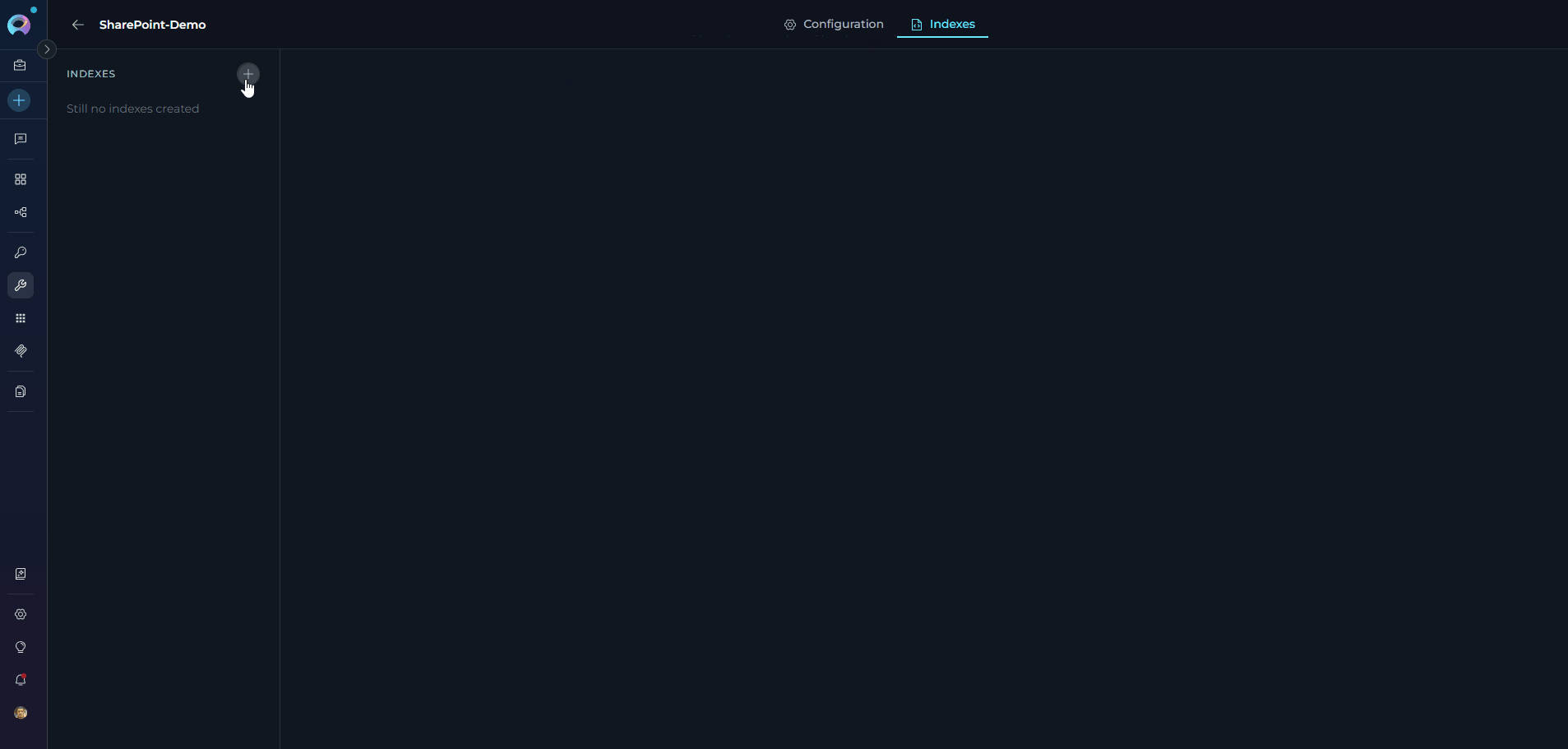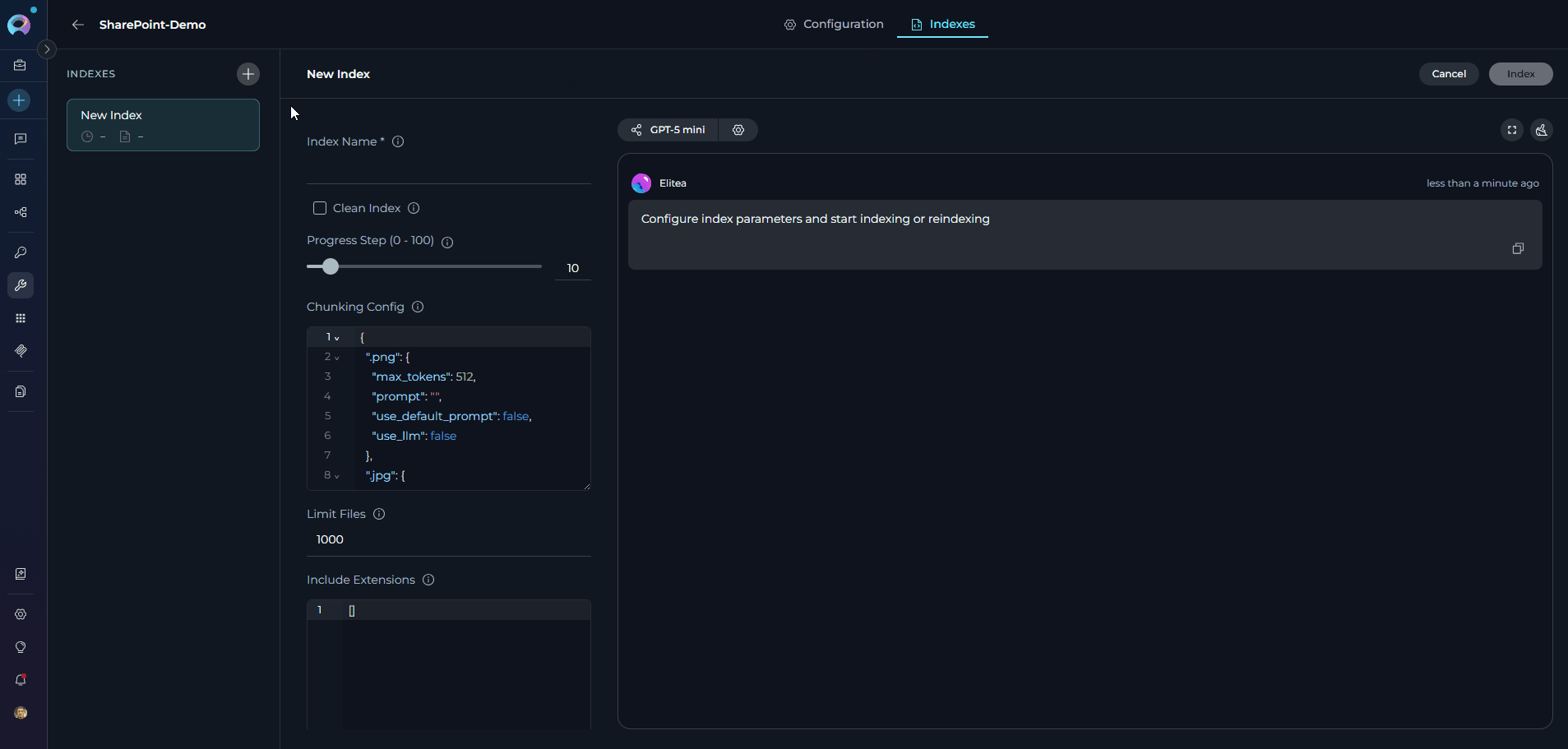
In the left sidebar, click + Create New Index — the creation form opens in the center panel.
-
Fill in the required and optional parameters for your SharePoint indexing:
The
onenote_filter parameter accepts a JSON object with the following optional keys:notebooks— list of notebook scope filters. Omit to index all notebooks. Each entry:{"id": "<notebook-id>", "sections": [{"id": "<section-id>", "pages": ["<page-id>", ...]}]}. Omitsectionsto include all sections; omitpagesto include all pages in a section.capture_images— boolean, defaulttrue. Whentrueand an LLM is configured, embedded images are described.include_attachments— boolean, defaultfalse. Whentrue, file attachments on OneNote pages are also indexed.
include_extensions and skip_extensions parameters.- Click Index to start the process.
-
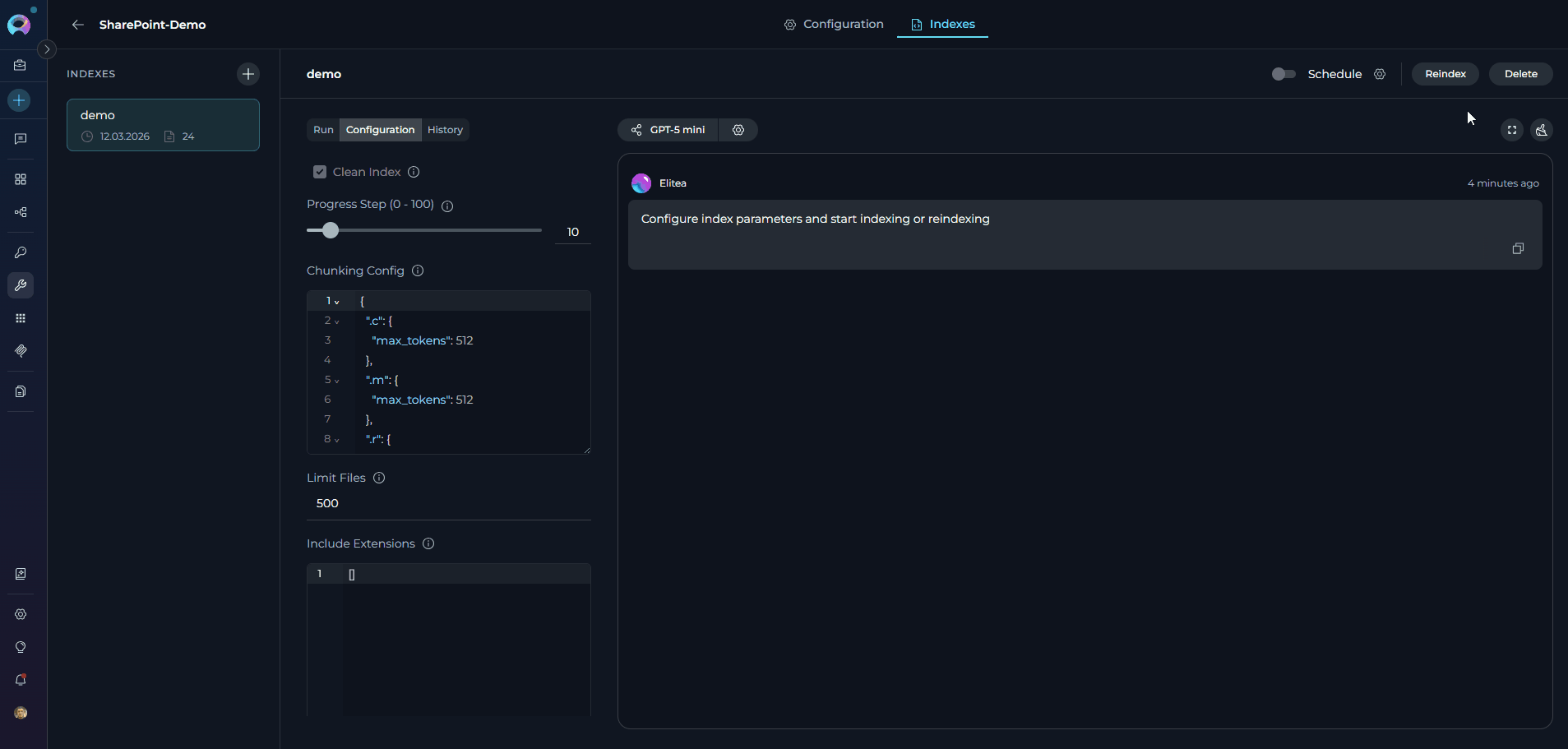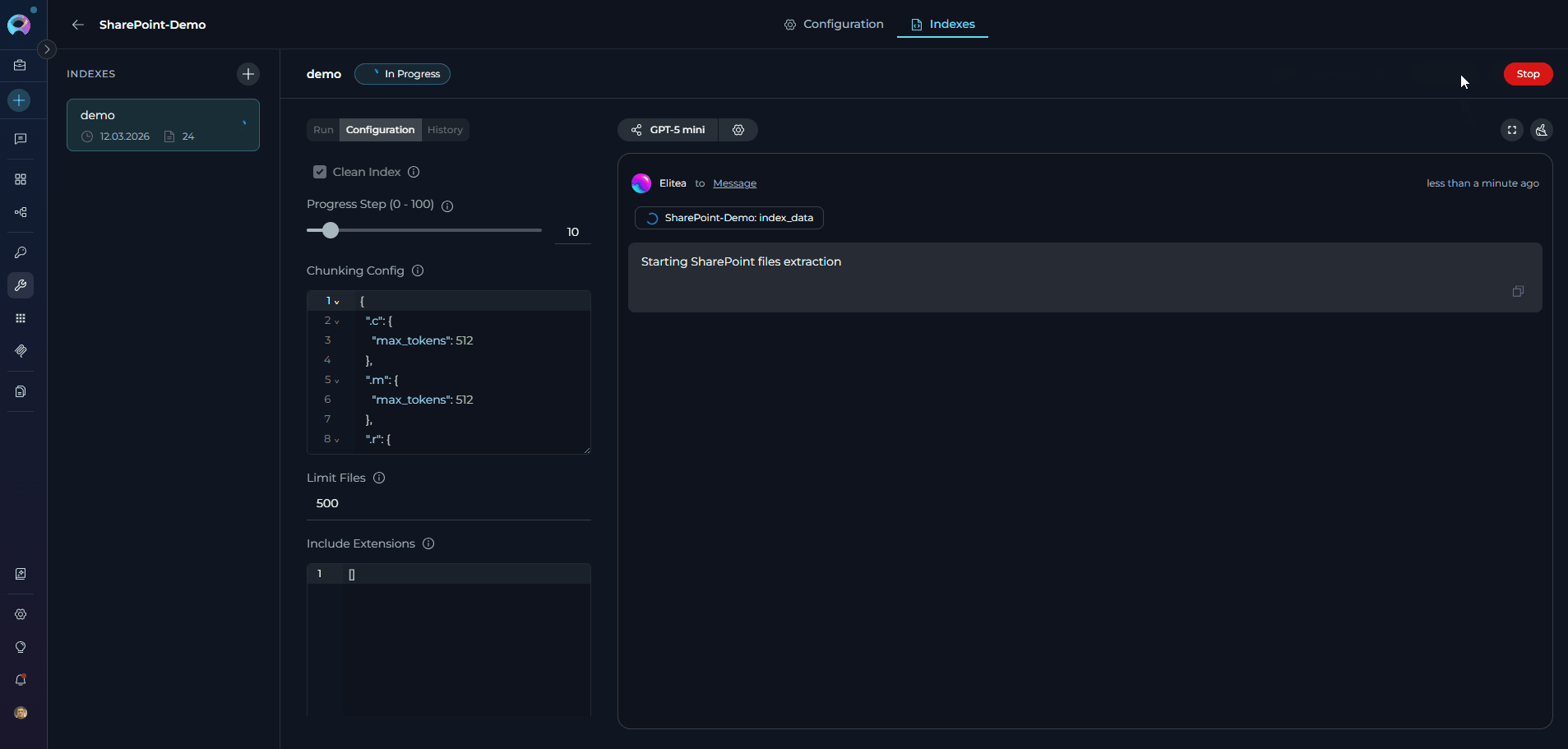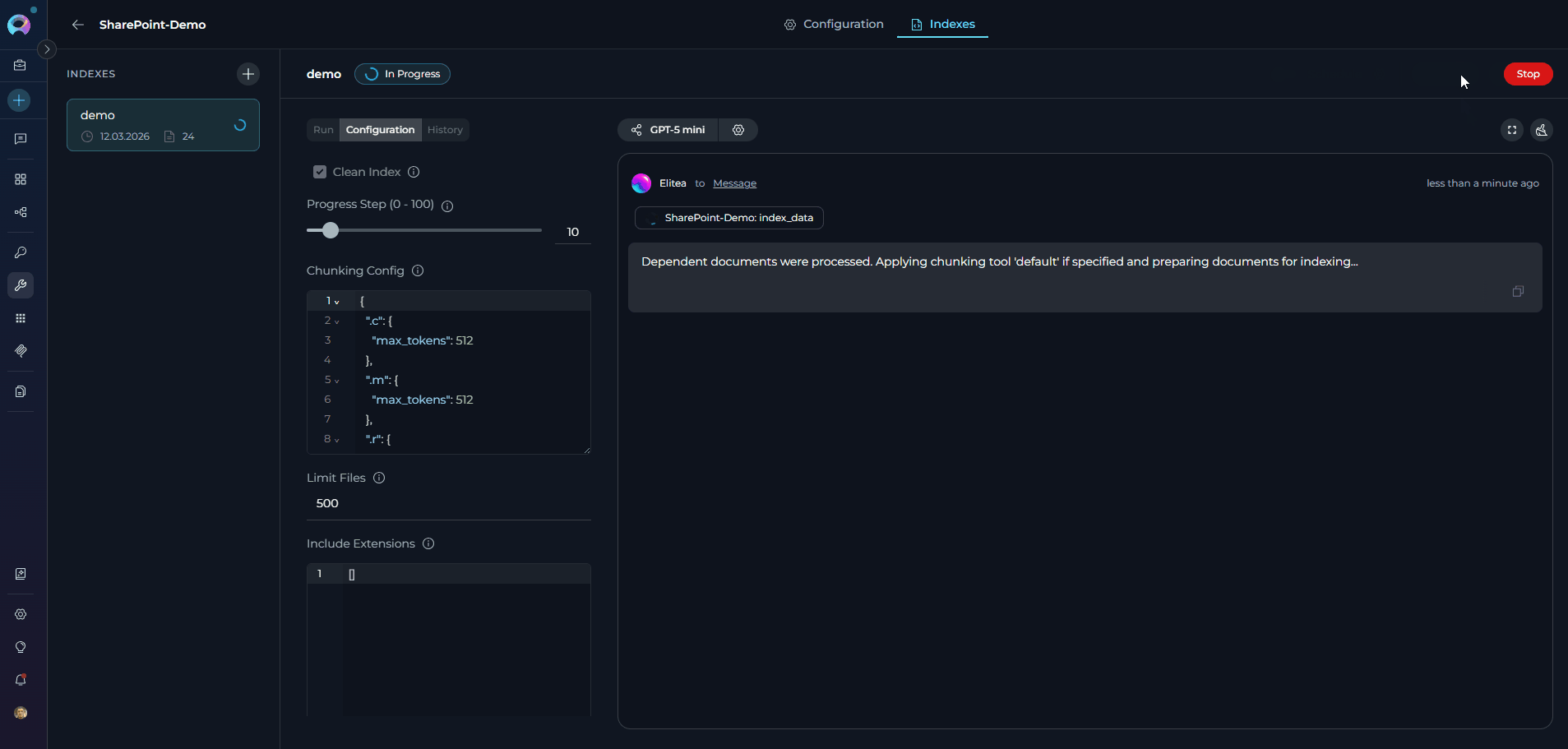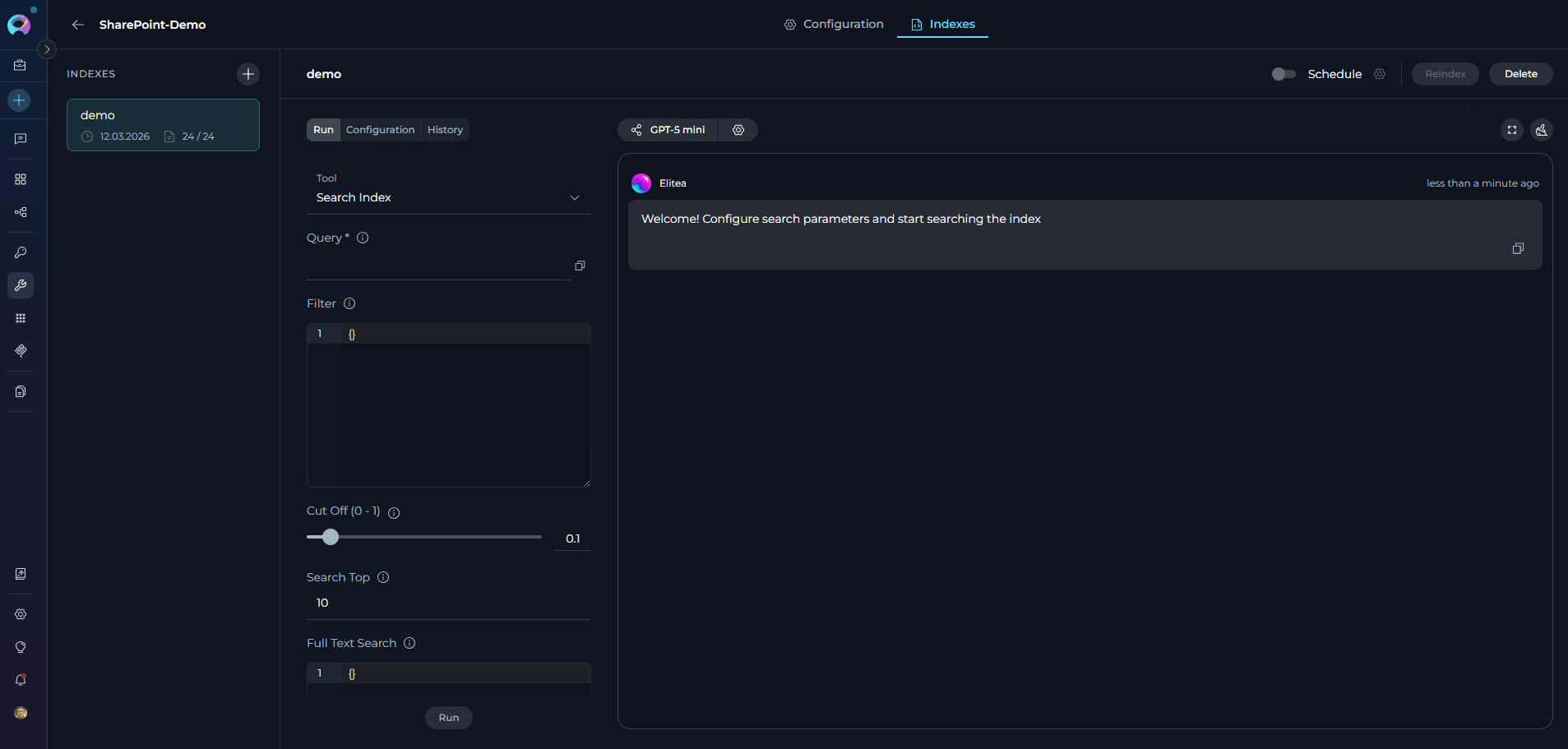
Monitor real-time status via the indicator on the index list item and detail header:
!!! tip “Stopping an indexing run” If indexing is in progress and the backend task ID is available, a Stop button appears in place of the Index button. Click Stop to cancel the current run. The index retains any documents successfully indexed before the stop.
Status Indicator Description In Progress 
Indexing is currently running Completed ✅ (no badge) All documents indexed successfully Partially Indexed ⚠️ “Partially indexed” badge Some documents indexed successfully; others failed Failed 
Indexing encountered a fatal error Stopped 
Indexing was manually cancelled 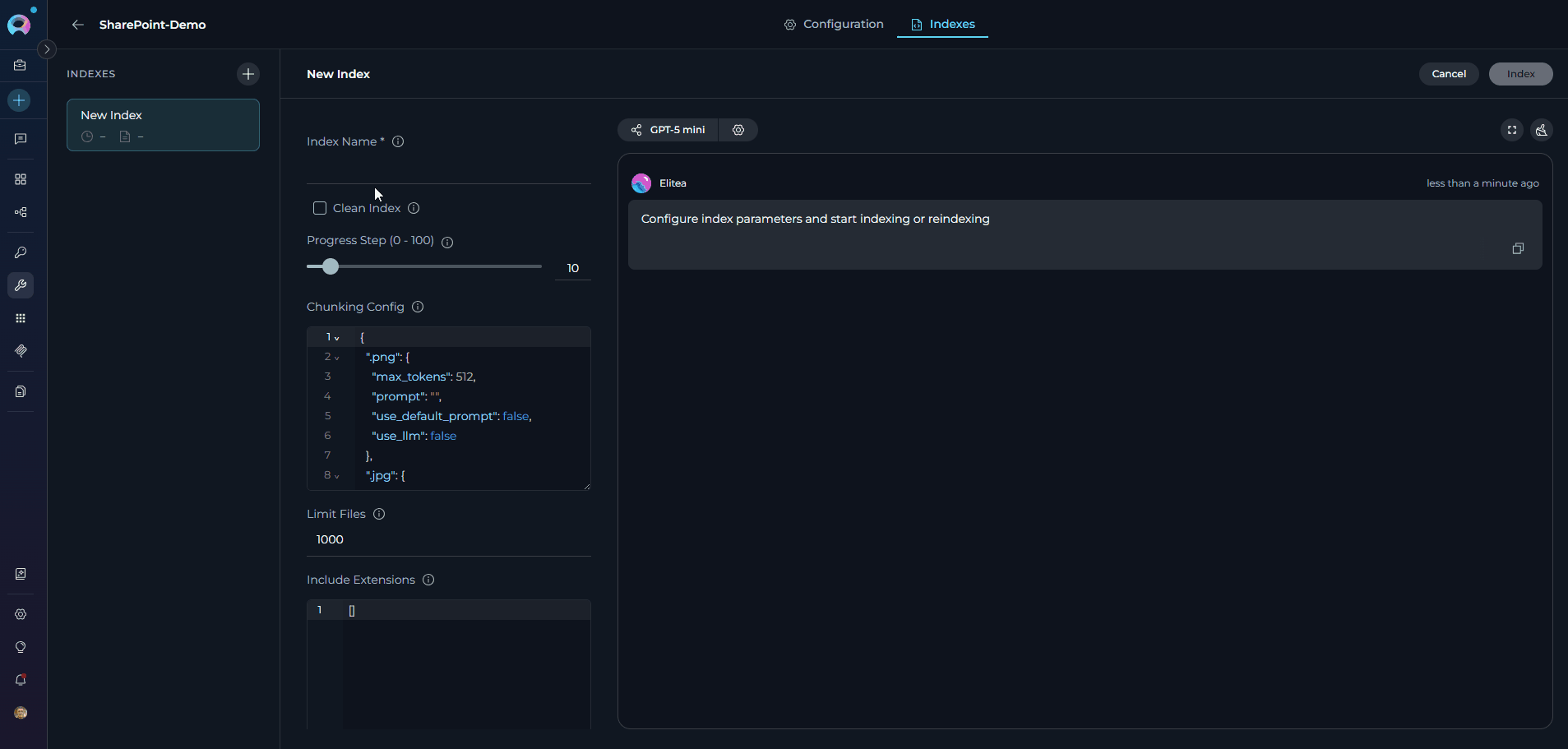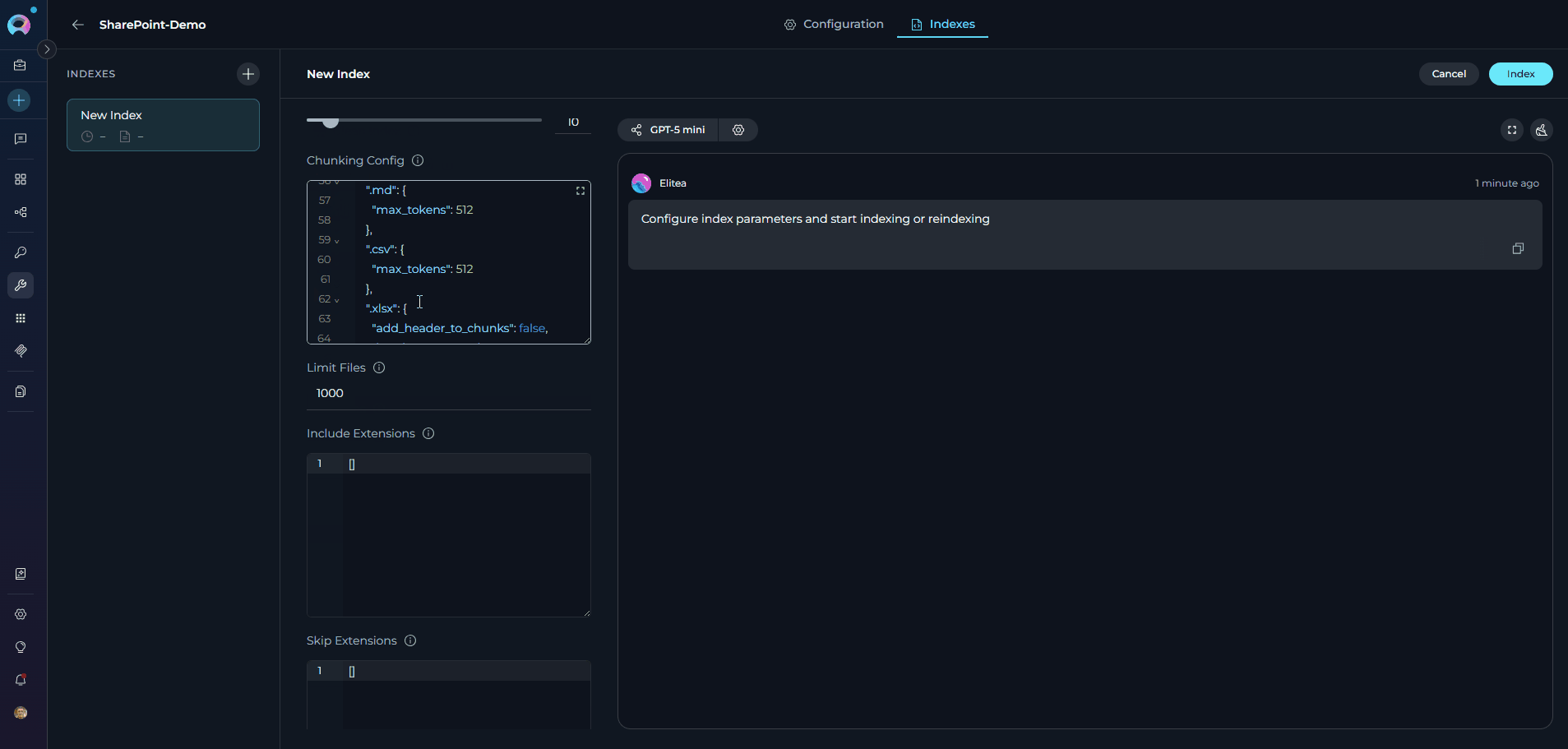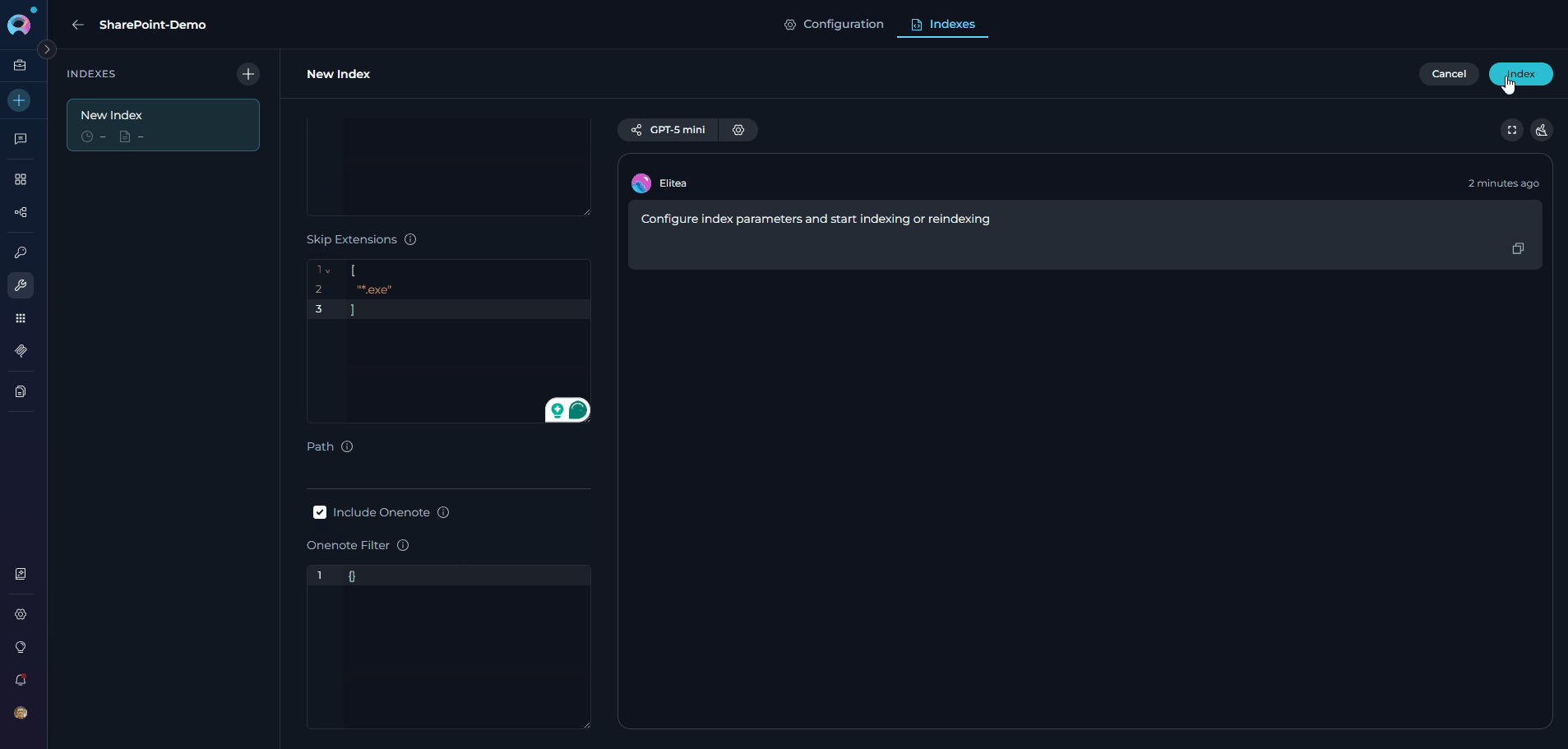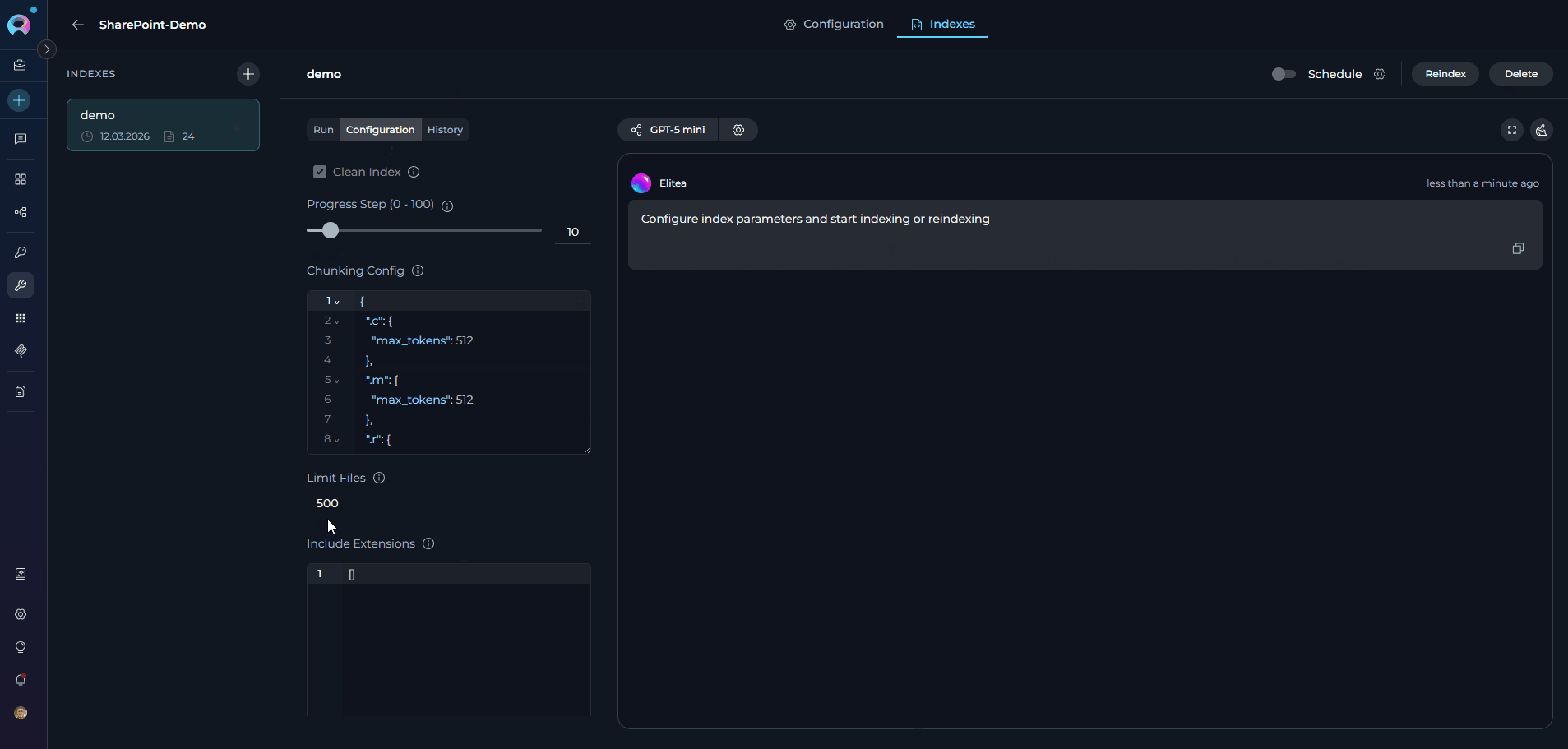
Managing Existing Indexes
Once an index exists, selecting it in the sidebar reveals a three-tab detail view:Reindexing
-
To refresh an existing index with updated SharePoint content, click the Reindex button (visible in the Run tab header of an existing index). Reindexing uses the same configuration as the original index. The history entry for the new run is added to the History tab.
Scheduling Automatic Reindexing
The Schedule toggle (visible when an existing index is selected) lets you enable cron-based automatic reindexing:- Click the gear icon next to the Schedule toggle to open the Schedule Settings dialog.
- Choose “Default” for a picker UI or “Advanced” to enter a cron expression directly.
- Optionally select specific credentials to use for scheduled runs.
- Click Apply to save the schedule, then enable the Schedule toggle.
0 0 * * 6 (every Saturday at midnight). Scheduling requires appropriate project permissions.
For a complete walkthrough of the scheduling feature, see Schedule Indexing.
Deleting an Index
-
Click the Delete button on an existing index to permanently remove all indexed data for that collection. The Remove index tool must be enabled in the toolkit for this button to be active.
Search and Chat with Indexed Data
Once your SharePoint data is indexed, you can use it in multiple ways:Using the Indexes Interface
Direct Search via Indexes Tab:- Access Indexes Tab: Navigate to your SharePoint toolkit → Indexes tab
- Select Index: Click on your created index from the sidebar
- Open Run Tab: Click the Run tab in the center panel
-
Choose Search Tool: Select from available search tools:
- Search Index: Basic semantic search
- Stepback Search Index: Advanced search with question breakdown
- Stepback Summary Index: Summarized insights from search results
- Enter Query: Type your natural language question
-
View Results: See responses with citations to specific SharePoint documents
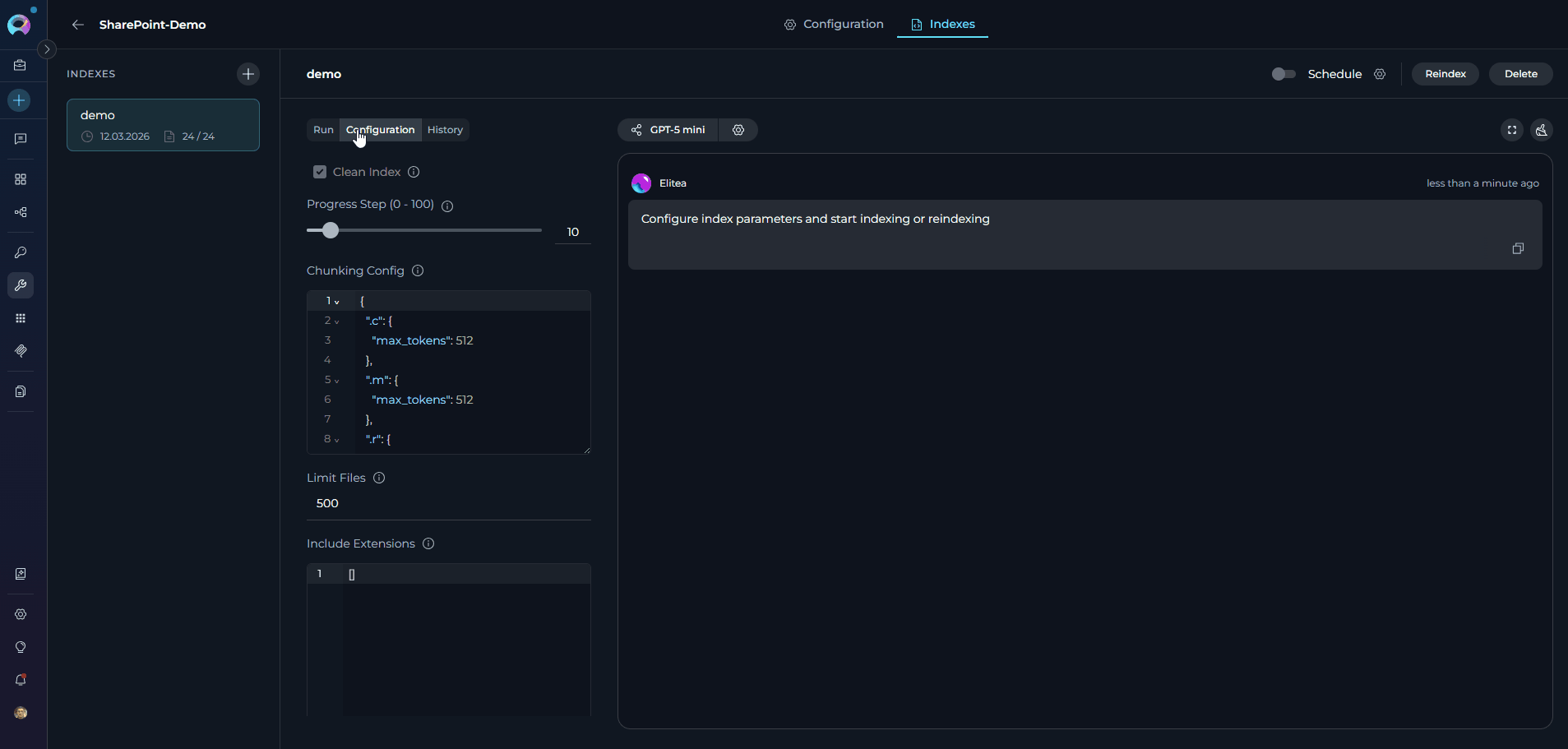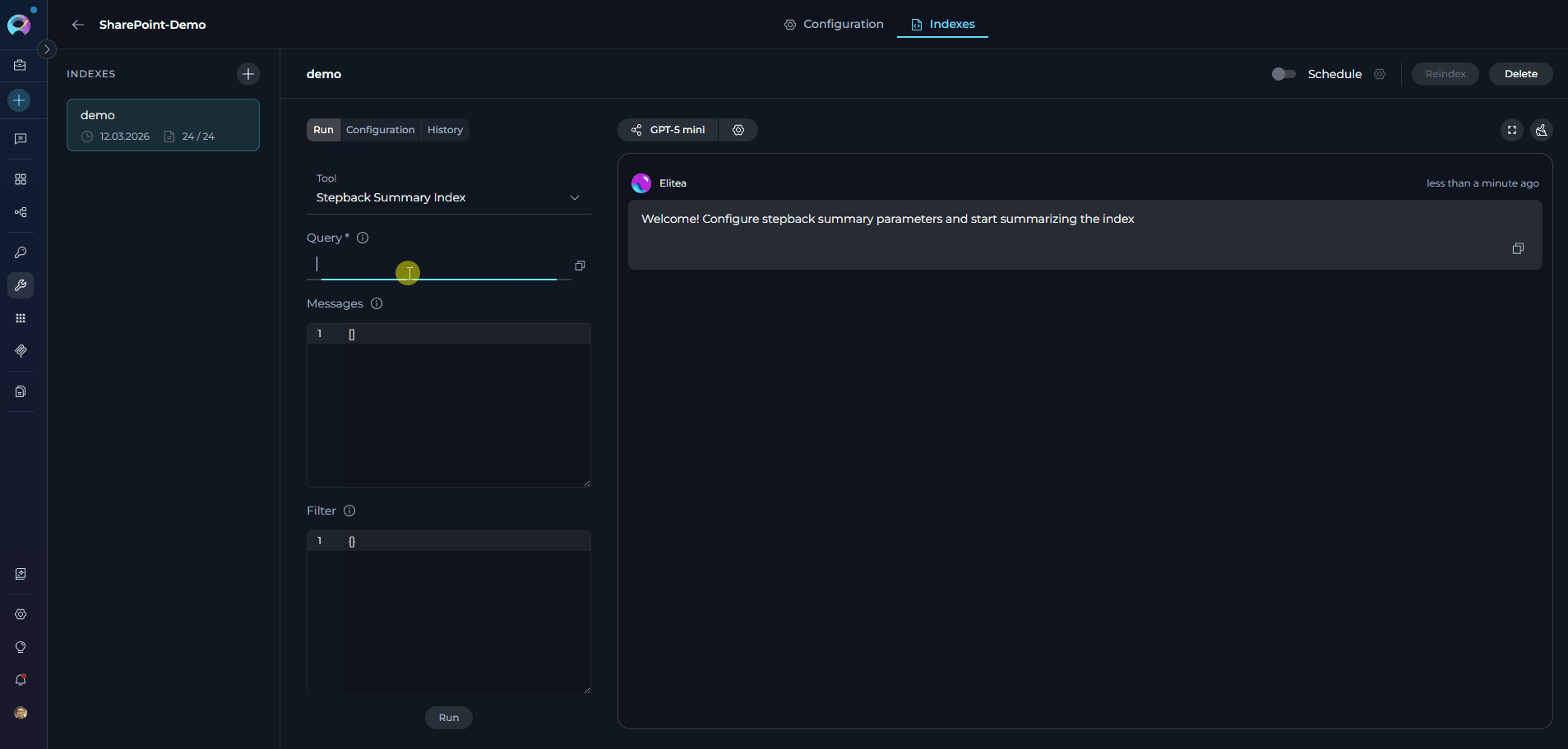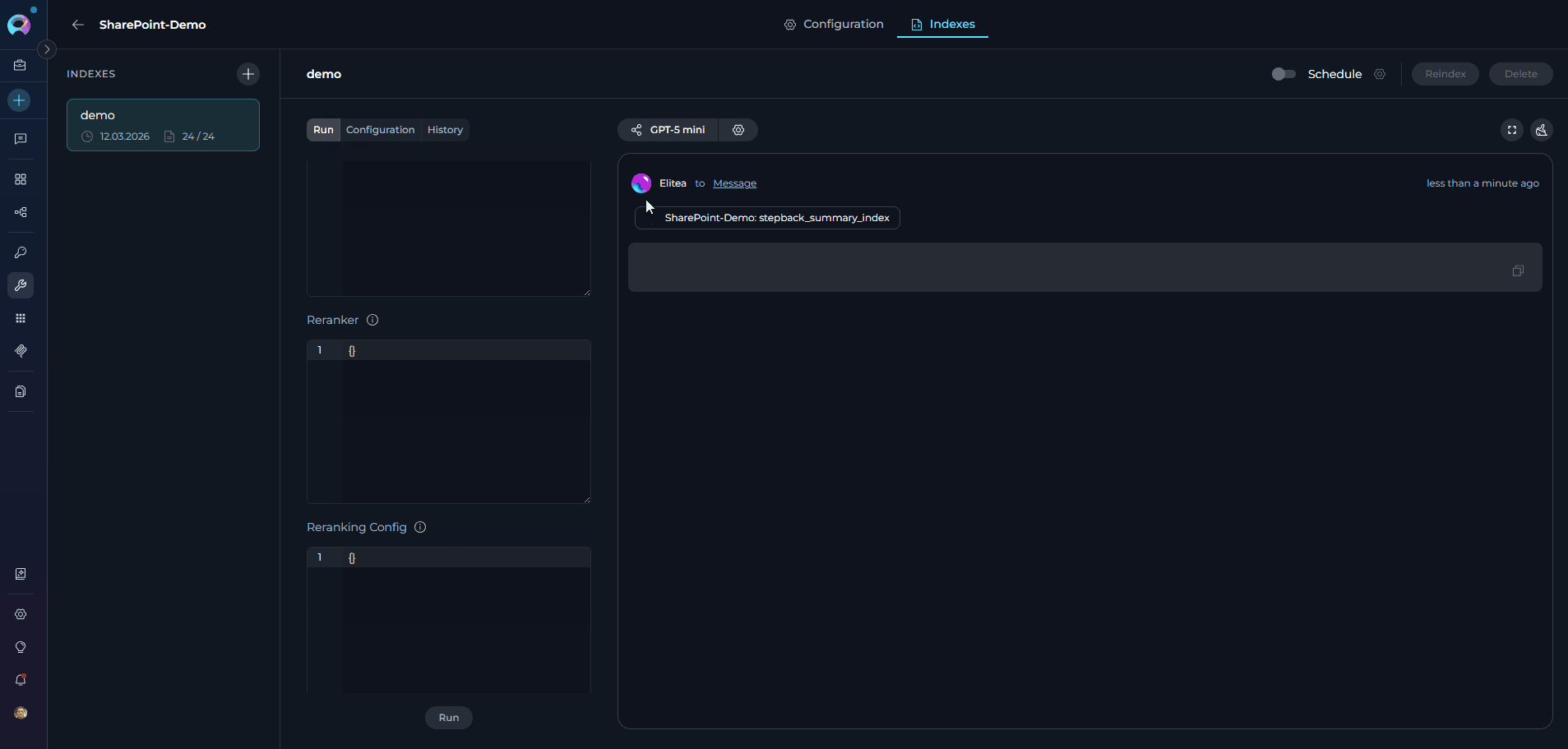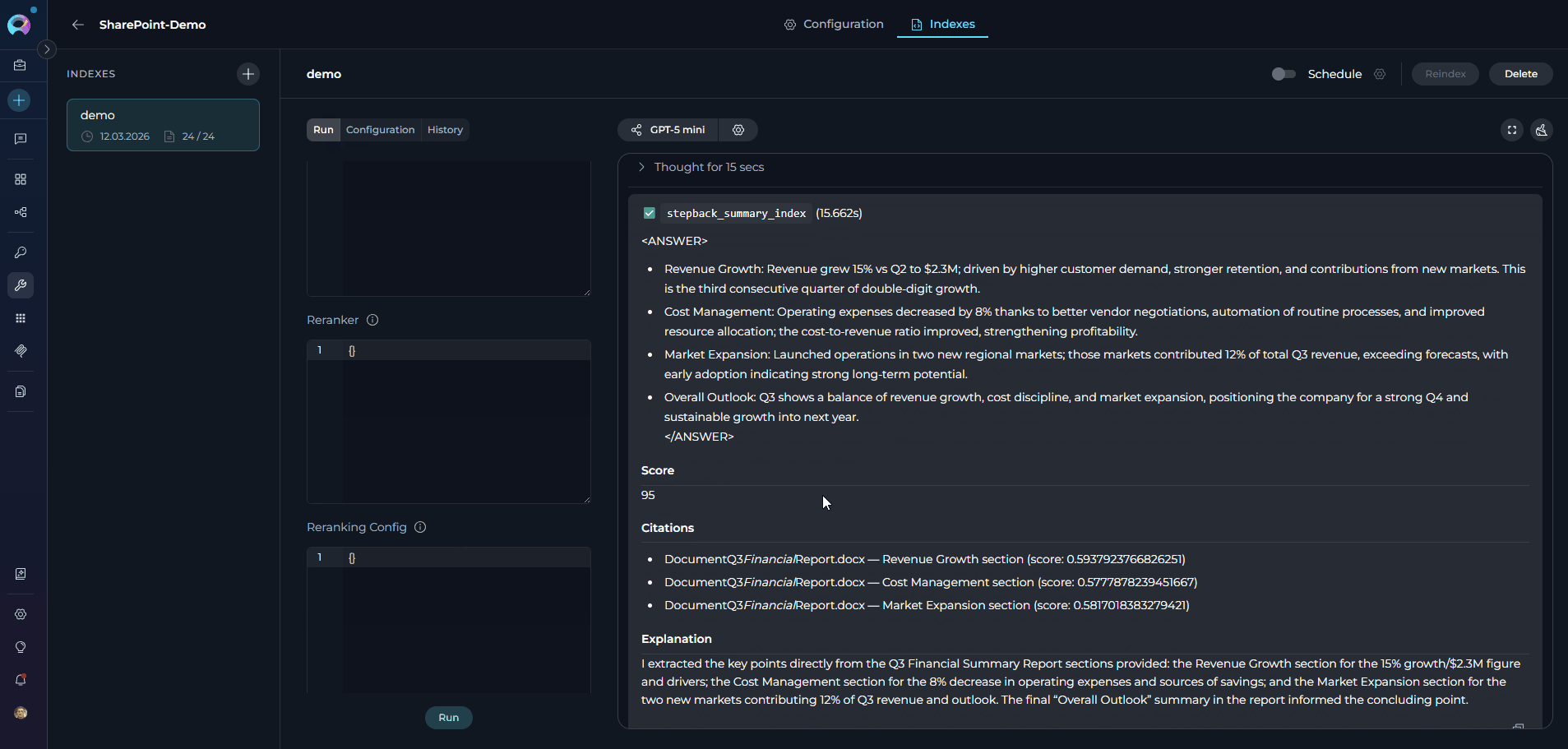
Using Toolkit in Conversations and Agents
Your SharePoint toolkit can be used in two main contexts:- In Conversations: Add the toolkit as a participant to ask questions and search your indexed SharePoint data
- In Agents: Include the toolkit when creating AI agents to give them access to your document data
- Start a New Conversation or Create an Agent
- Add Toolkit as Participant: Select your SharePoint toolkit from the available toolkits
-
Ask Natural Language Questions: The toolkit will automatically search your indexed data and provide relevant answers with citations
Real-Life Example Workflow
The following examples show a typical end-to-end flow: indexing documents, verifying the index, and querying the content — all through a conversation with the SharePoint toolkit added.User:
“Index all documents from our SharePoint site with suffix ‘docs’. Include Word and PDF files but skip image files. Clean any existing index first.”
User: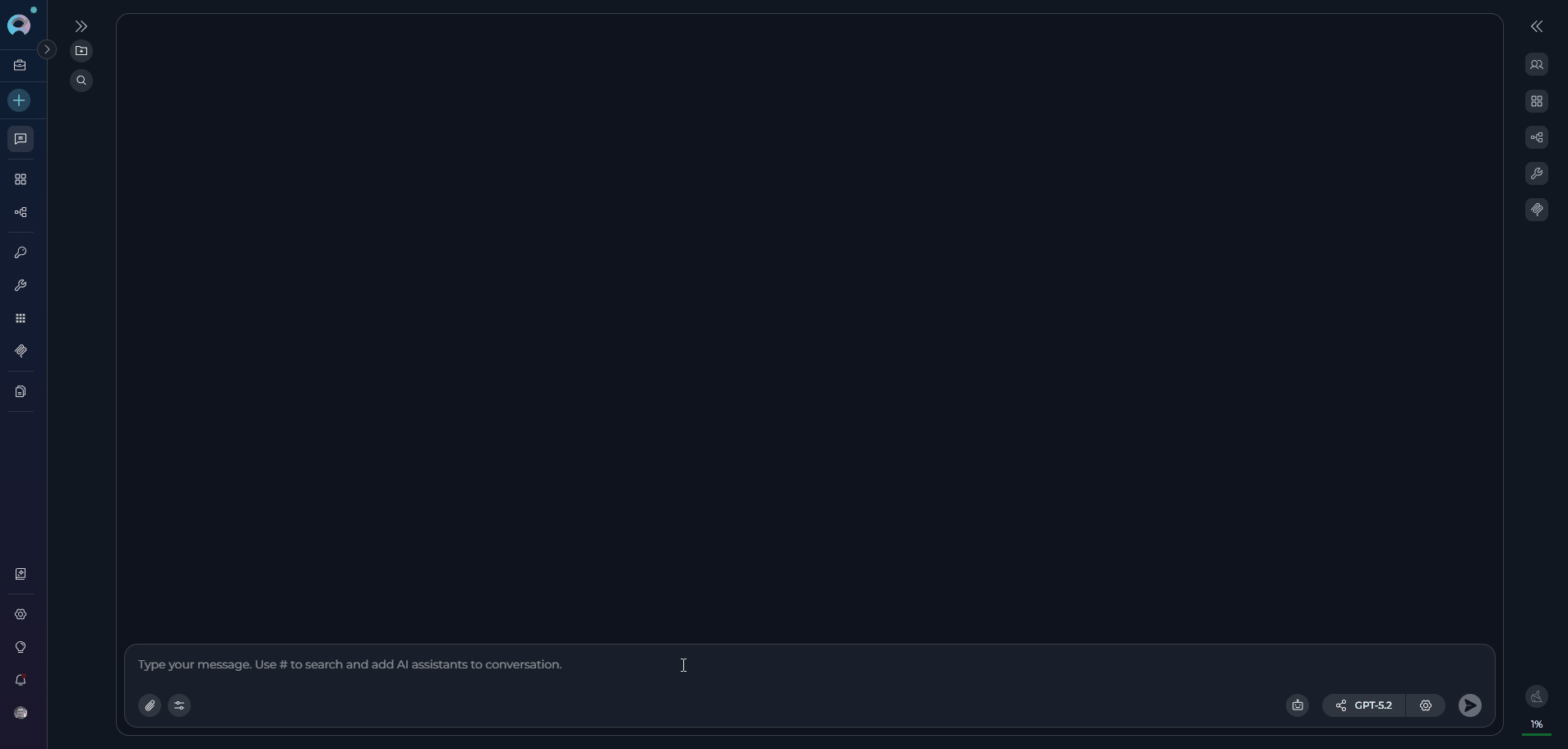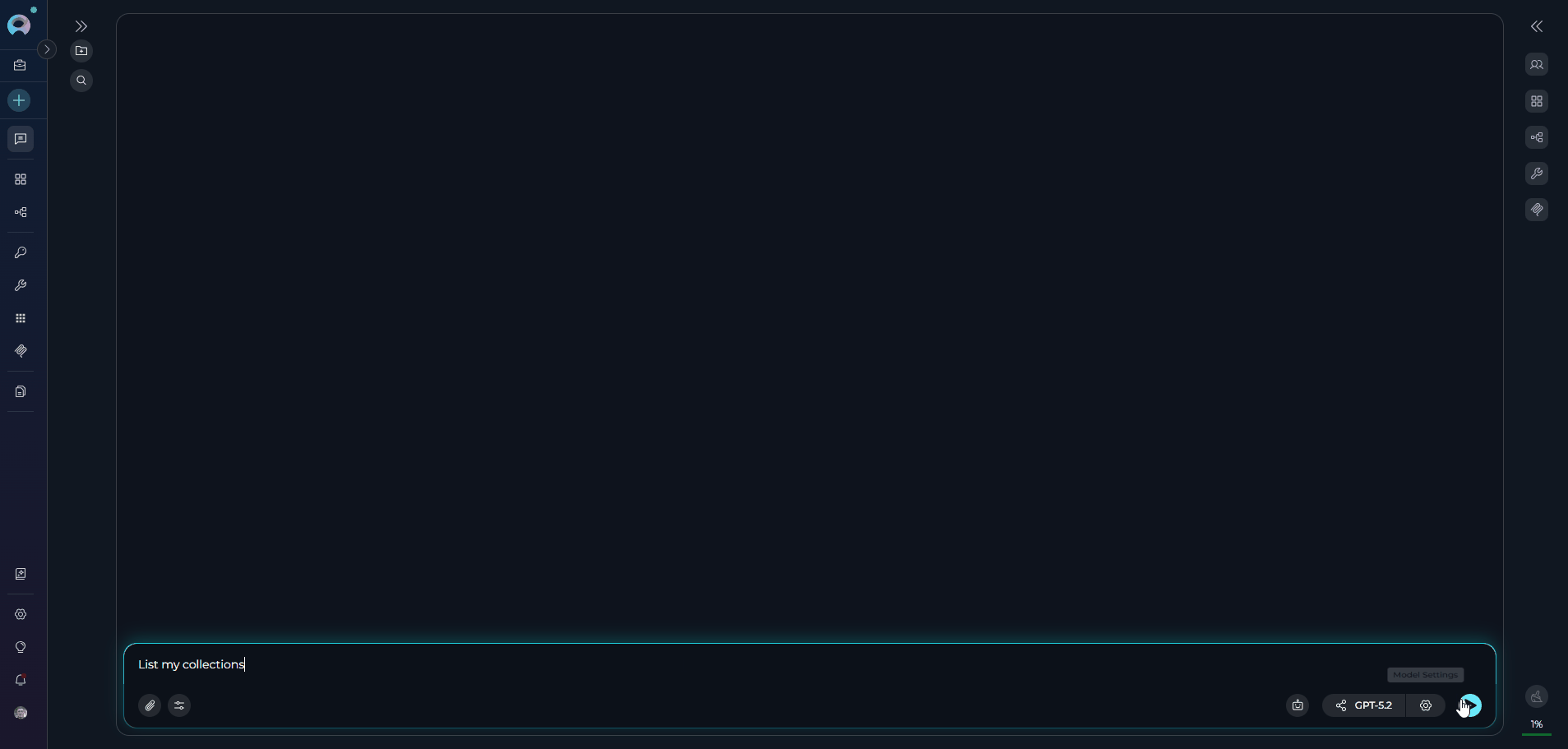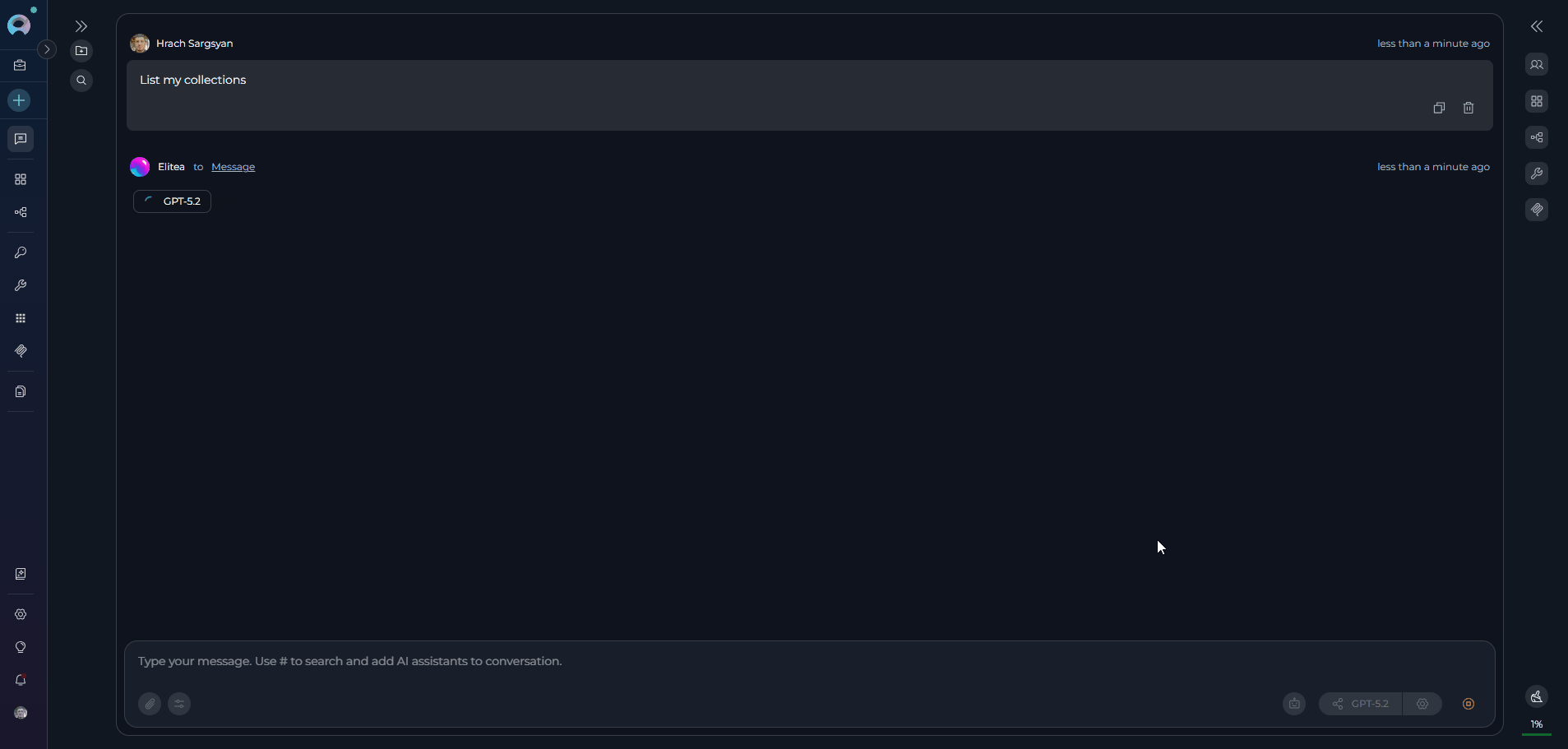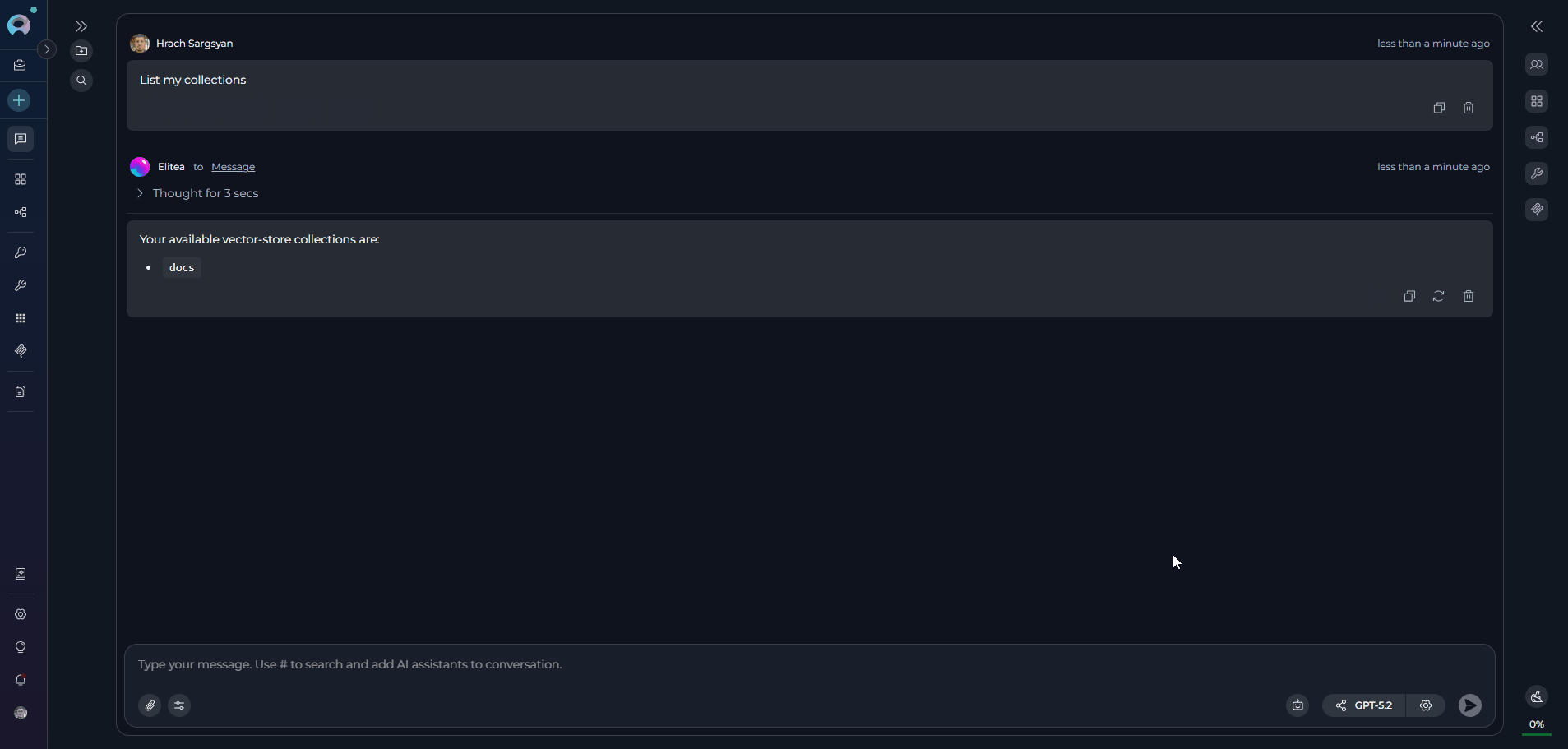
“List my collections”
User: “What are the key points from our Q3 financial report?”SharePoint Toolkit: “Based on your indexed documents, here are the key points from the Q3 financial report: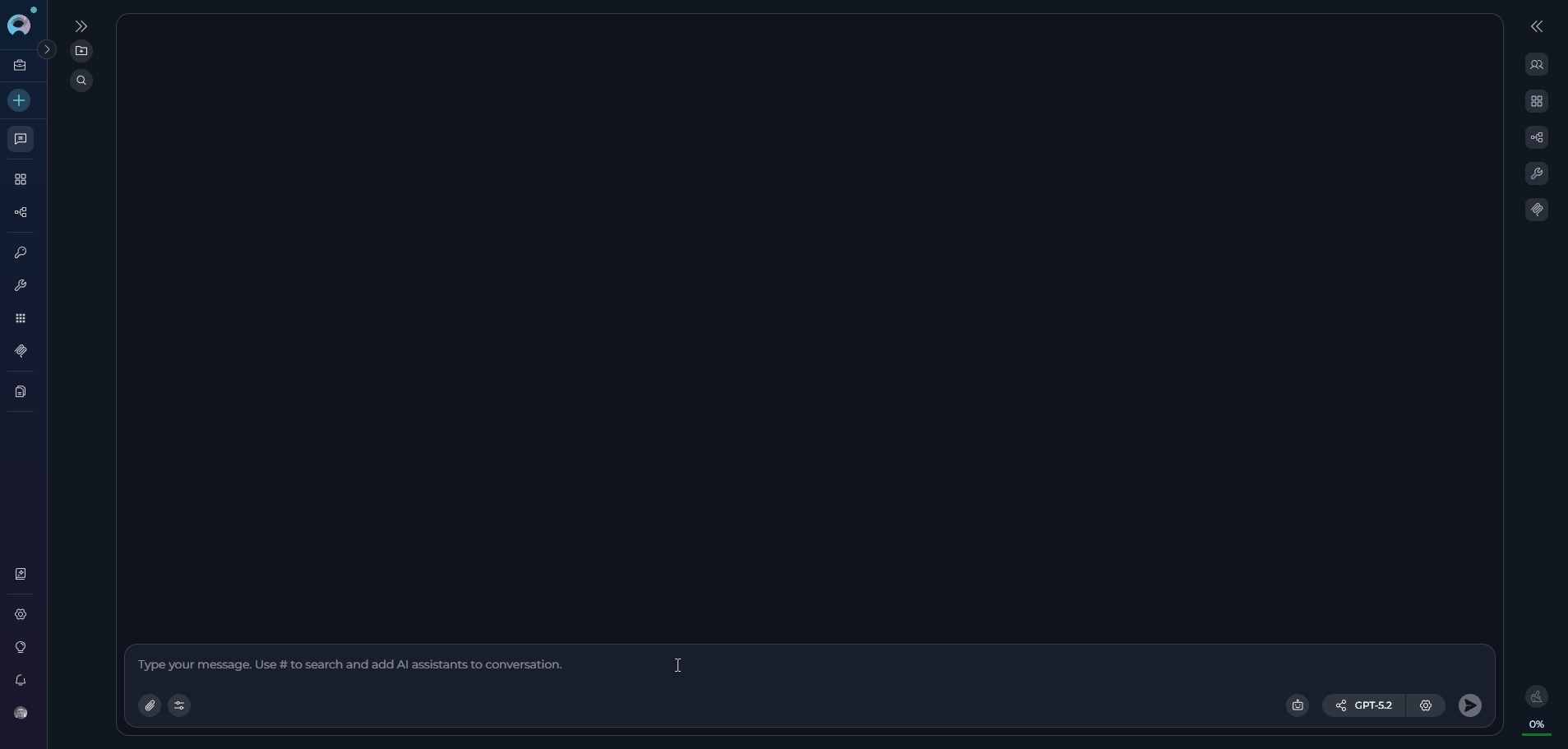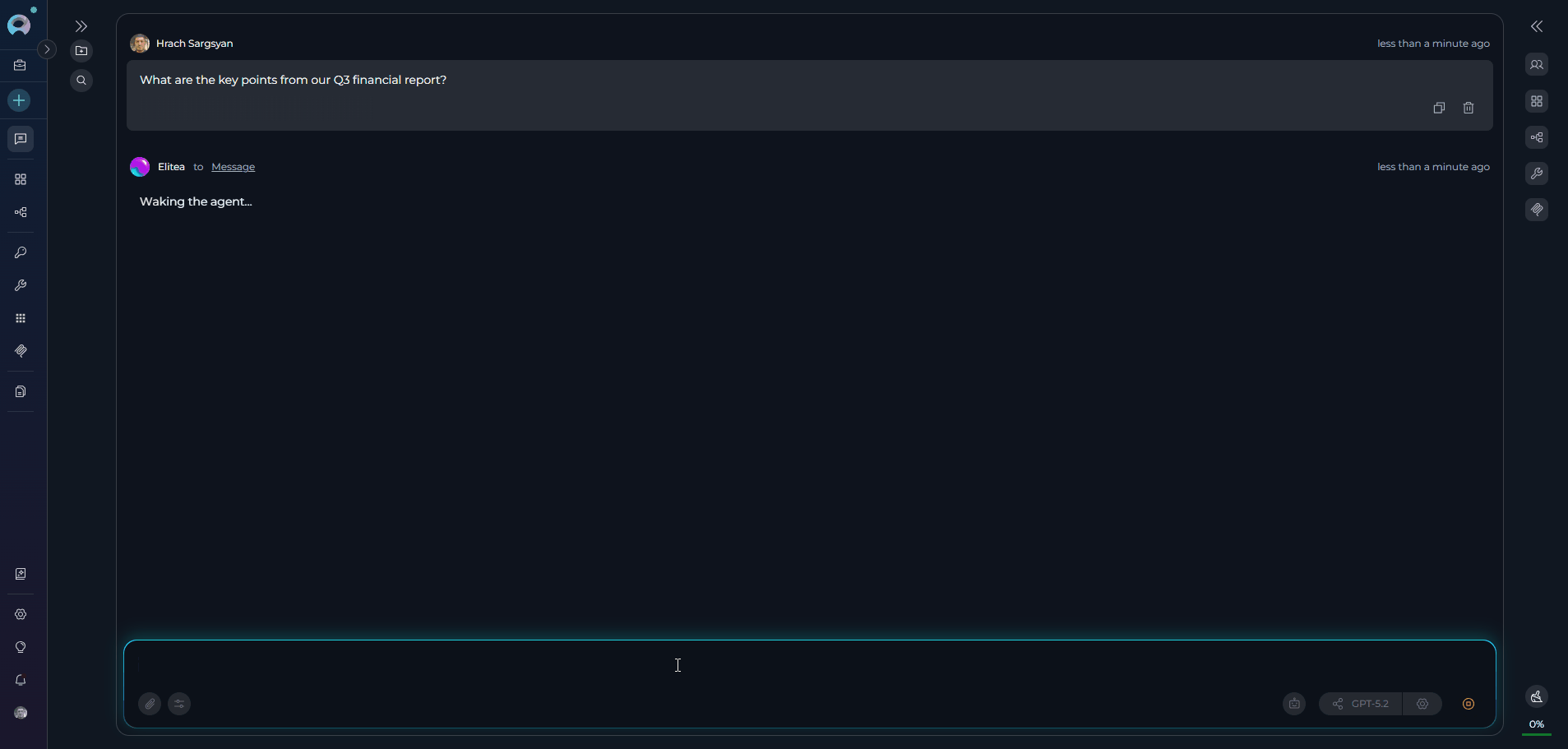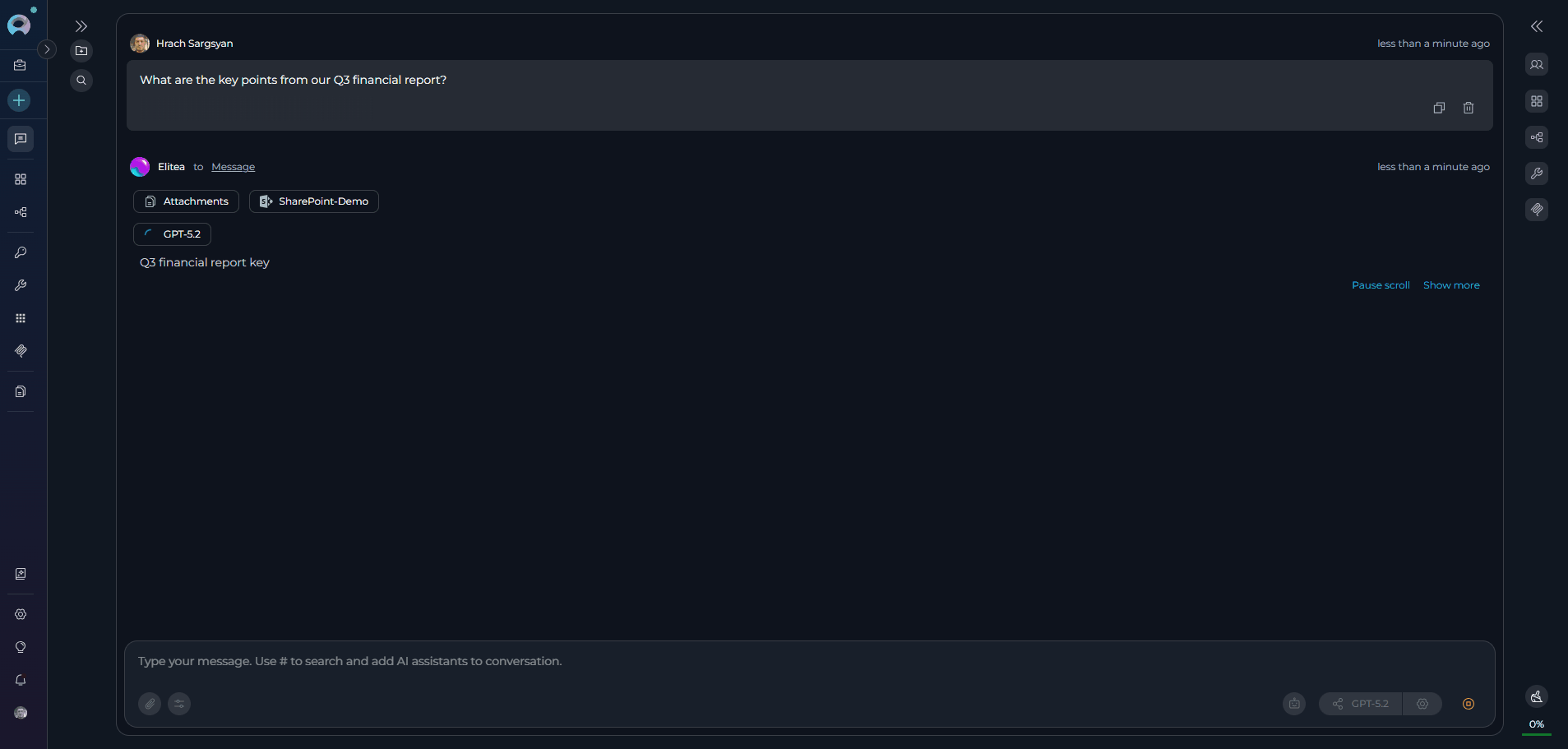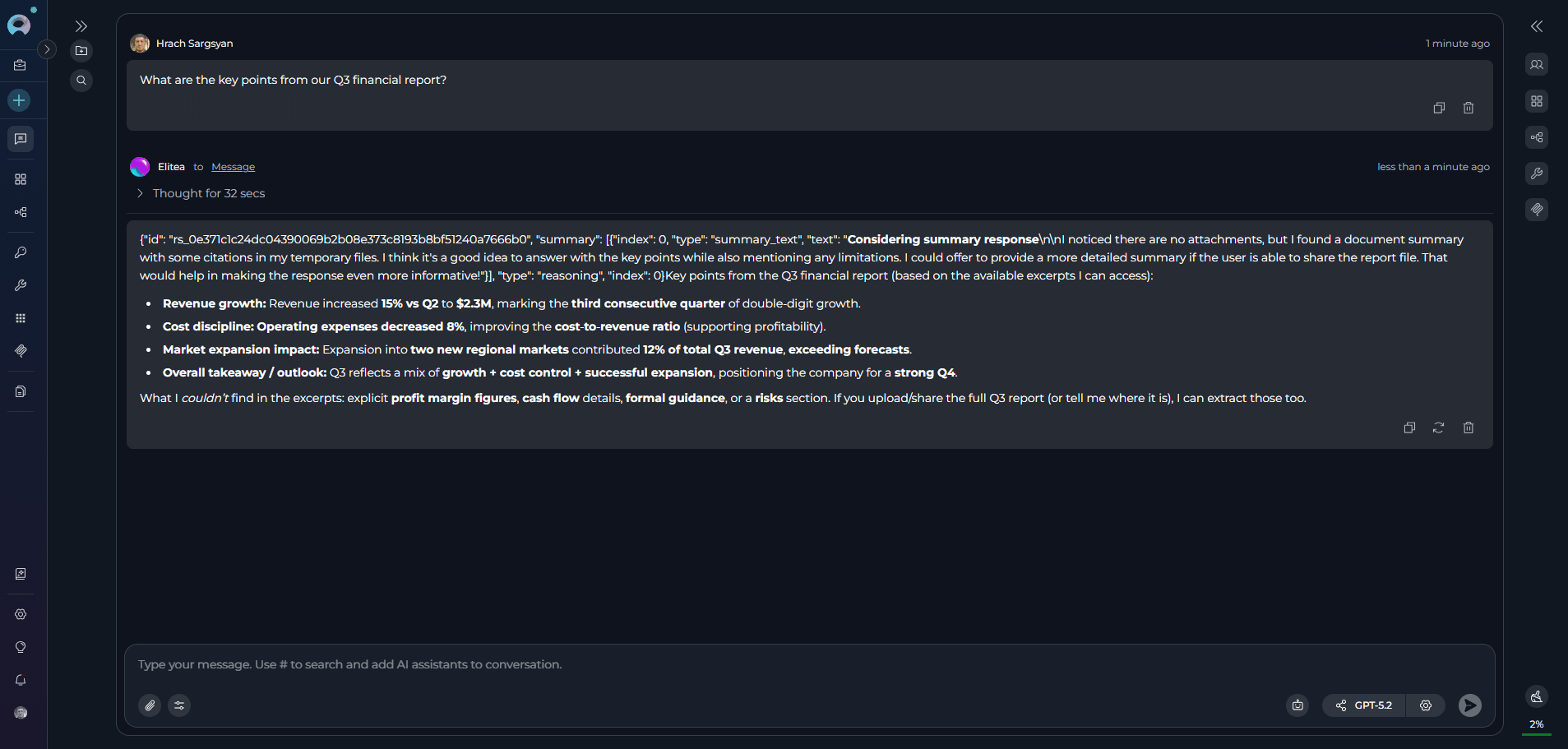
- Revenue Growth: 15% increase compared to Q2, reaching $2.3M total revenue
- Cost Management: Operating expenses reduced by 8% through efficiency initiatives
- Market Expansion: Successful launch in two new regional markets contributing 12% of revenue
- User: “Find me the latest project management templates”
-
SharePoint Toolkit: “Here are the latest project management templates from your indexed documents:
Templates Found:
- Project Charter Template v3.2: Comprehensive project initiation document with stakeholder analysis
- Sprint Planning Template: Agile project management with backlog and capacity planning
- Risk Management Matrix: Template for identifying and tracking project risks
- Pre-formatted sections for scope, objectives, and deliverables
- Built-in formulas for timeline and resource calculations
- Integration with company branding and approval workflows
Troubleshooting
Common Errors and SolutionsIndexes Tab Not Visible or Tab Disabled
Indexes Tab Not Visible or Tab Disabled
- Verify PgVector and Embedding Model are configured in Settings → AI Configuration
- Ensure the Index Data tool is enabled in your SharePoint toolkit configuration
- Check that your toolkit supports indexing (SharePoint is supported)
- Refresh the browser page and retry
Site Not Found or Access Denied to Site
Site Not Found or Access Denied to Site
- Verify the SharePoint site URL is correct and accessible
- Ensure your Azure AD app has been granted permissions to the specific site collection using AppInv.aspx
- Check that the site collection exists and is not archived or deleted
- Confirm your app registration has the necessary SharePoint API permissions
No Files Indexed or Empty Document Library
No Files Indexed or Empty Document Library
- Check that the document library contains accessible files
- Verify file extensions are not being filtered out by the Skip Extensions parameter
- Ensure your app has read permissions to the document library
- Try indexing without extension filters first, then add restrictions
- Check the Limit Files parameter — a value of
0disables file collection entirely; use the default (1000) or a positive number
Vector Database Connection Failed or PgVector Errors
Vector Database Connection Failed or PgVector Errors
- Ensure PgVector is properly configured in Settings → AI Configuration
- Verify the vector database is running and accessible
- Check connection credentials and database permissions
- Restart the vector database service if connection issues persist
Index Name Validation Error (Exceeds 7 Characters)
Index Name Validation Error (Exceeds 7 Characters)
Cause: The
index_name field has a hard limit of 7 characters enforced by the SDK. Providing a longer value will cause a Pydantic validation error before indexing starts.- Keep the Index Name to 7 characters or fewer (e.g.,
docs,sp2024,hr) - Leave the field blank to use the default collection name without a suffix
- Use short abbreviations for descriptive names (e.g.,
fininstead offinance)
File Processing Errors or Document Parsing Failures
File Processing Errors or Document Parsing Failures
Individual file-level parse errors are non-fatal — the SDK logs them as warnings and continues indexing remaining files. The final result will report a partial count if some files failed.
- Large files may cause timeouts; consider using file size limits or Skip Extensions
- Binary files (executables, archives) should be excluded via Skip Extensions
- Check available storage space for the vector database
- Verify document formats are supported (Word, PDF, Excel, PowerPoint, text files)
- Review application logs for specific file paths that failed to parse
Search Returns Few or No Results
Search Returns Few or No Results
- Lower the cut-off score from 0.5 to 0.35 or 0.3
- Increase search_top from 10 to 20 or 30
- Try rephrasing your query with document-specific terms (file names, content types)
- Verify the indexed content contains relevant information for your query
Improving Search Quality
Improving Search Quality
- Include multiple document types for comprehensive coverage
- Use natural language queries rather than exact file names
- Leverage stepback search for complex business questions that require reasoning
- Create separate indexes for different content types (current vs archived, public vs restricted)
Business Documents
Business Documents
- Focus on current documents: exclude outdated templates and archived files
- Include metadata-rich content: documents with proper titles, descriptions, and tags
- Index both working documents and finalized reports for complete coverage
Project Management
Project Management
- Include project templates, status reports, and planning documents
- Index across multiple project sites for portfolio-level insights
- Consider including both active and completed projects for lessons learned
Knowledge Management
Knowledge Management
- Include policy documents, procedures, and training materials
- Index FAQ documents and troubleshooting guides for support scenarios
- Focus on documents with high business value and frequent access patterns
For additional information and detailed setup instructions, see:
- Indexing Overview - General indexing concepts and features
- Create a Credential - Step-by-step credential creation guide
- How to Use Credentials - Credential management and SharePoint setup
- Toolkits Menu - Toolkit configuration and management
- SharePoint Toolkit Integration Guide - Complete SharePoint toolkit reference
- AI Configuration - Vector storage and embedding model setup
- Chat Menu - Creating conversations and adding toolkit participants