Overview
The Context Budget widget displays real-time token usage metrics across Chat conversations, Agent runs, Pipeline executions, and Application configurations, providing immediate visibility into context consumption and management status. Context management is enabled by default for all projects — no configuration is required to start using it. The Context Budget widget appears automatically once an active conversation exists.To use context management, you need:
- An active conversation in Chat, Agent, Pipeline, or Application
- LLM model configured with context management support
Accessing Context Management
Context management is available in multiple locations within ELITEA:From Chat Conversations
Monitor and control context during active conversations:- Navigate to Chat → Conversations in the main menu
- Select or create a conversation
- Send the first message to initiate the conversation
- The Context Budget widget appears in the right panel (bottom left) after the first message
- The widget displays real-time token usage and management status
-
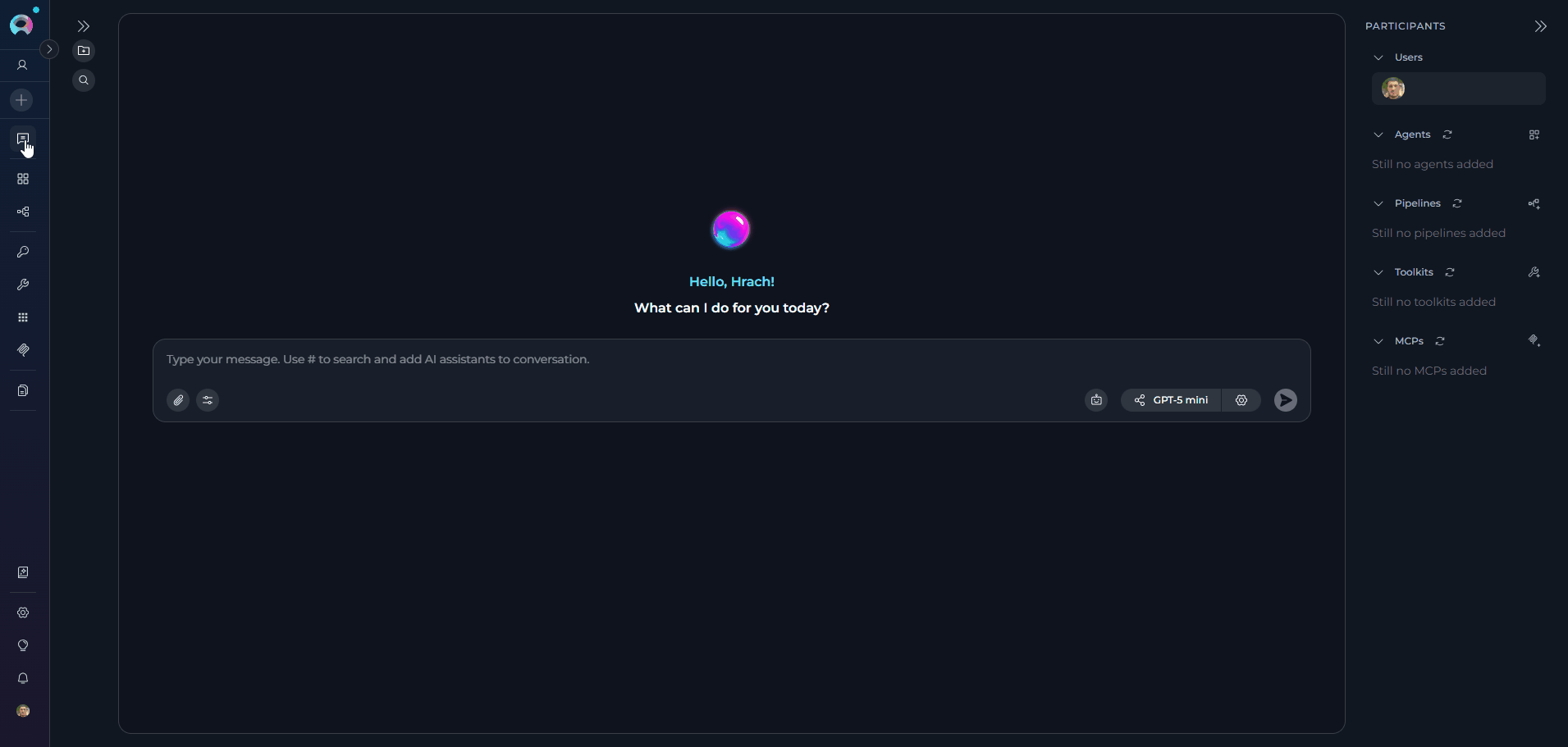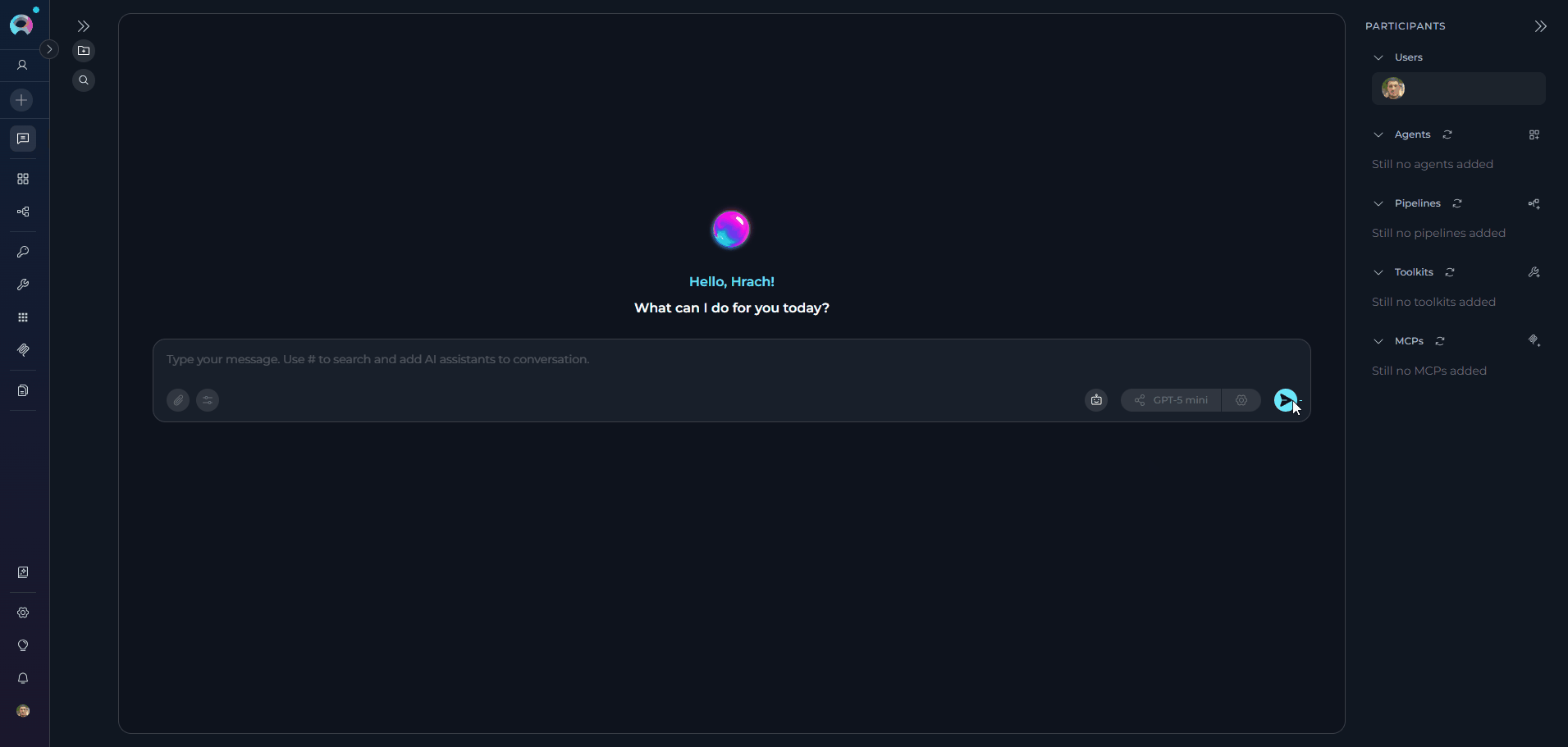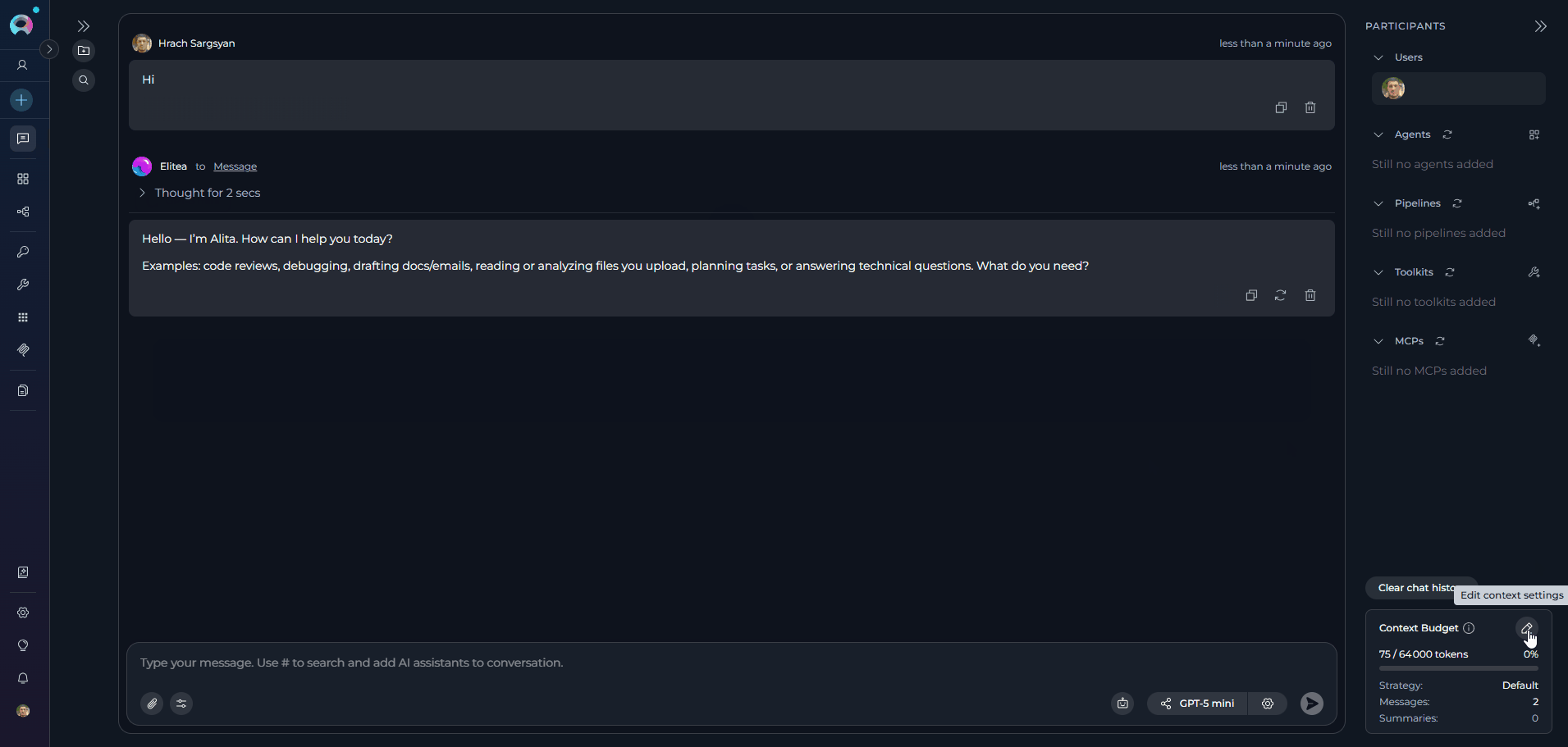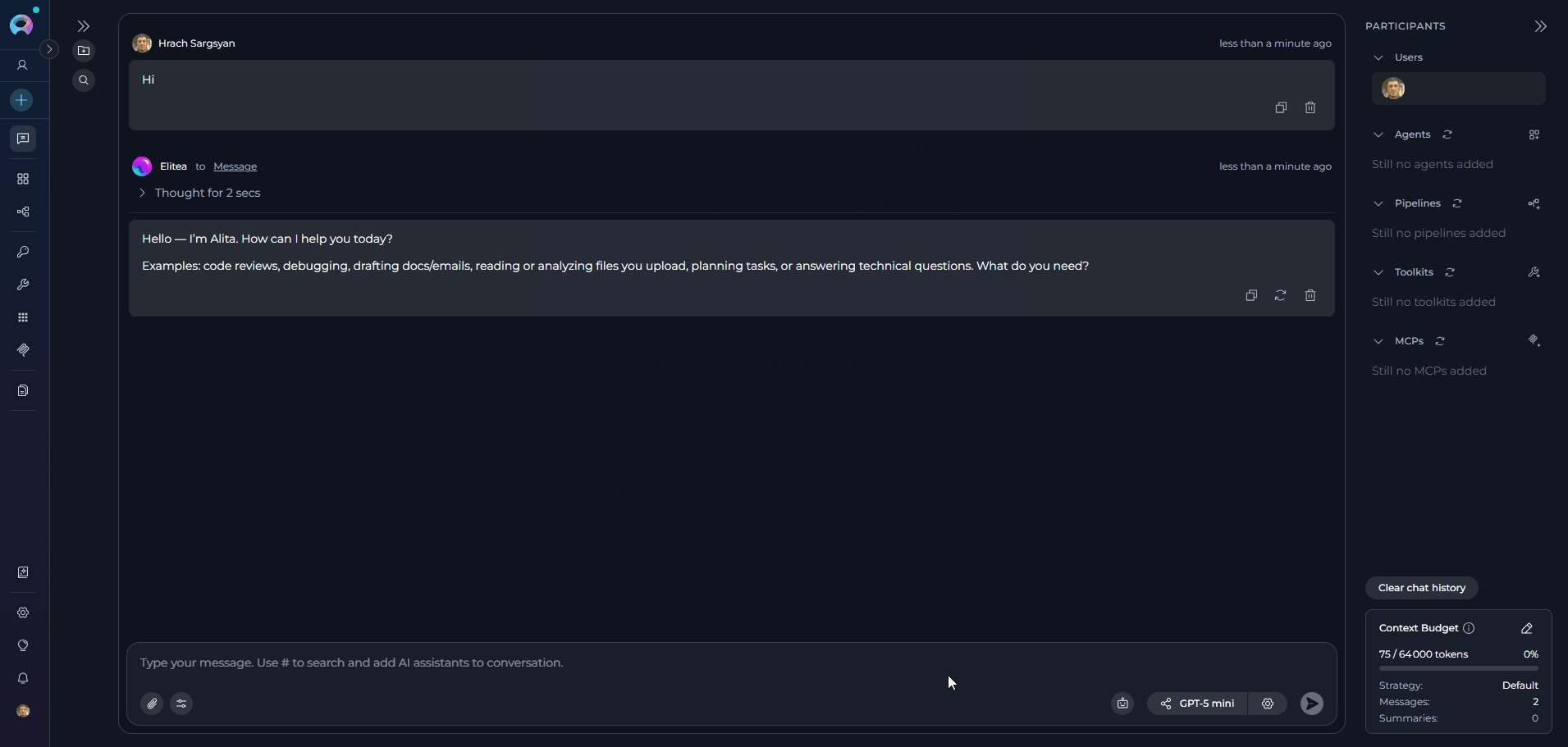
Click on the widget to view detailed metrics and controls
In Agent Runs
Track context usage during agent execution:- Navigate to Agents and select an agent
- Send the first message to initiate the conversation
- The Context Budget widget appears above the chat panel interface after the first message
- Monitor token consumption as the agent processes requests
-
View pruning and summarization activity in real-time
In Pipeline Executions
Monitor context during pipeline chat panels:- Navigate to Pipelines and select a pipeline
- Open the pipeline’s chat panel interface
- Send the first message to initiate the conversation
- The Context Budget widget appears above the chat panel interface after the first message
- Track context usage across pipeline node executions
-
Observe automatic context management as the pipeline runs
Understanding the Context Budget Widget
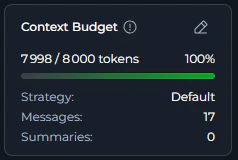
The Context Budget widget provides three view modes that display progressively more detailed information. Collapsed View-
The minimal view shows essential token usage at a glance:

- Green: Normal usage (0-100%)
- Orange: High usage (more than 100%)
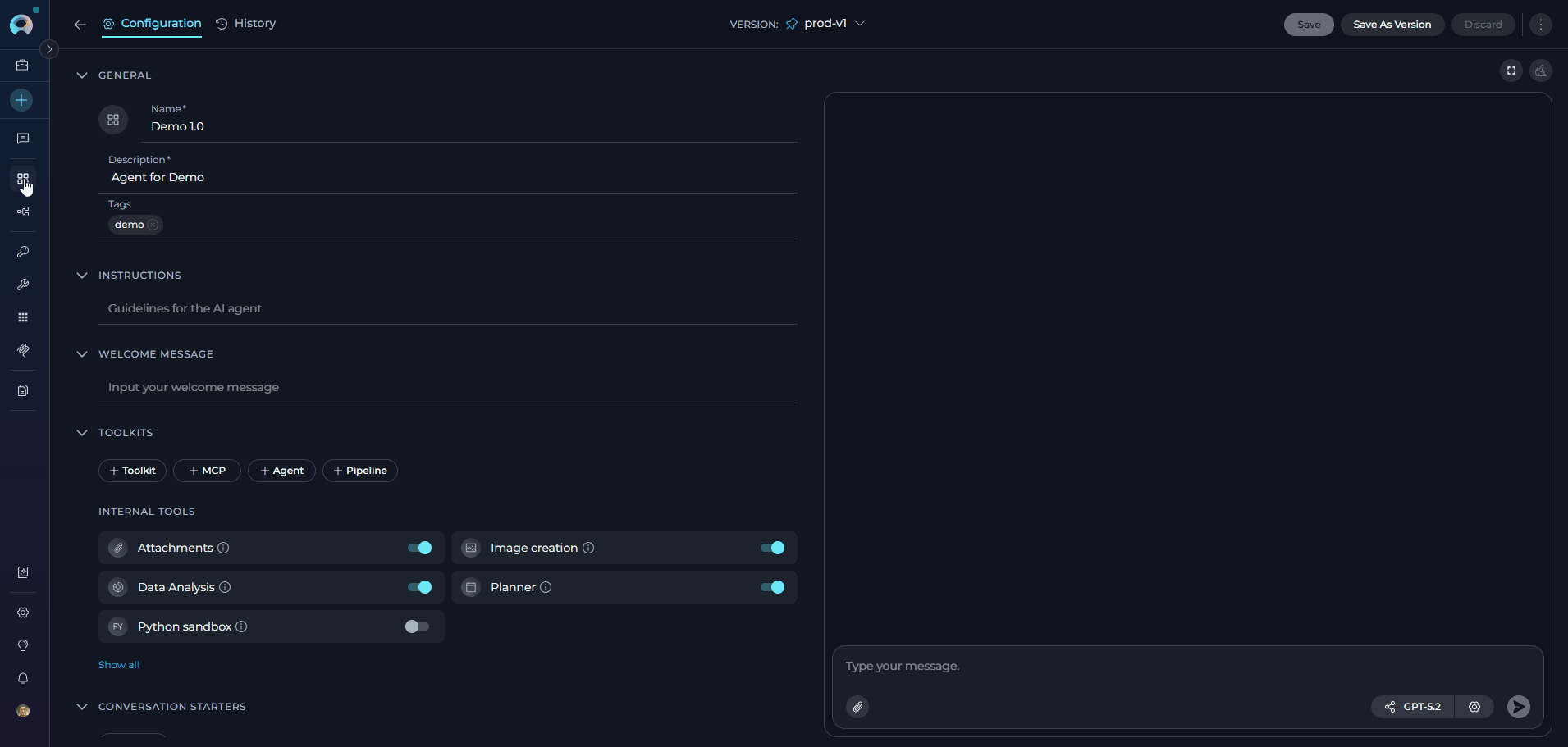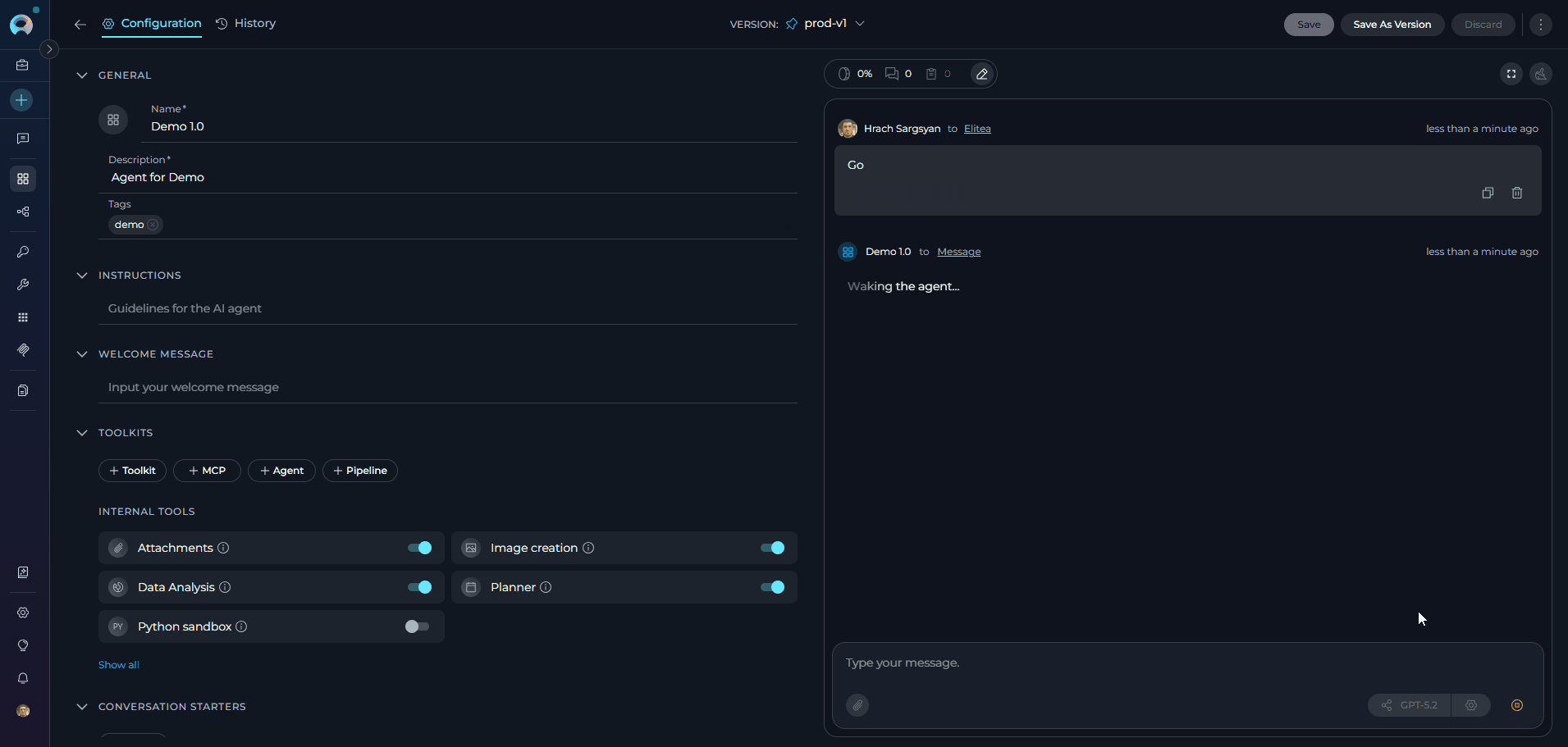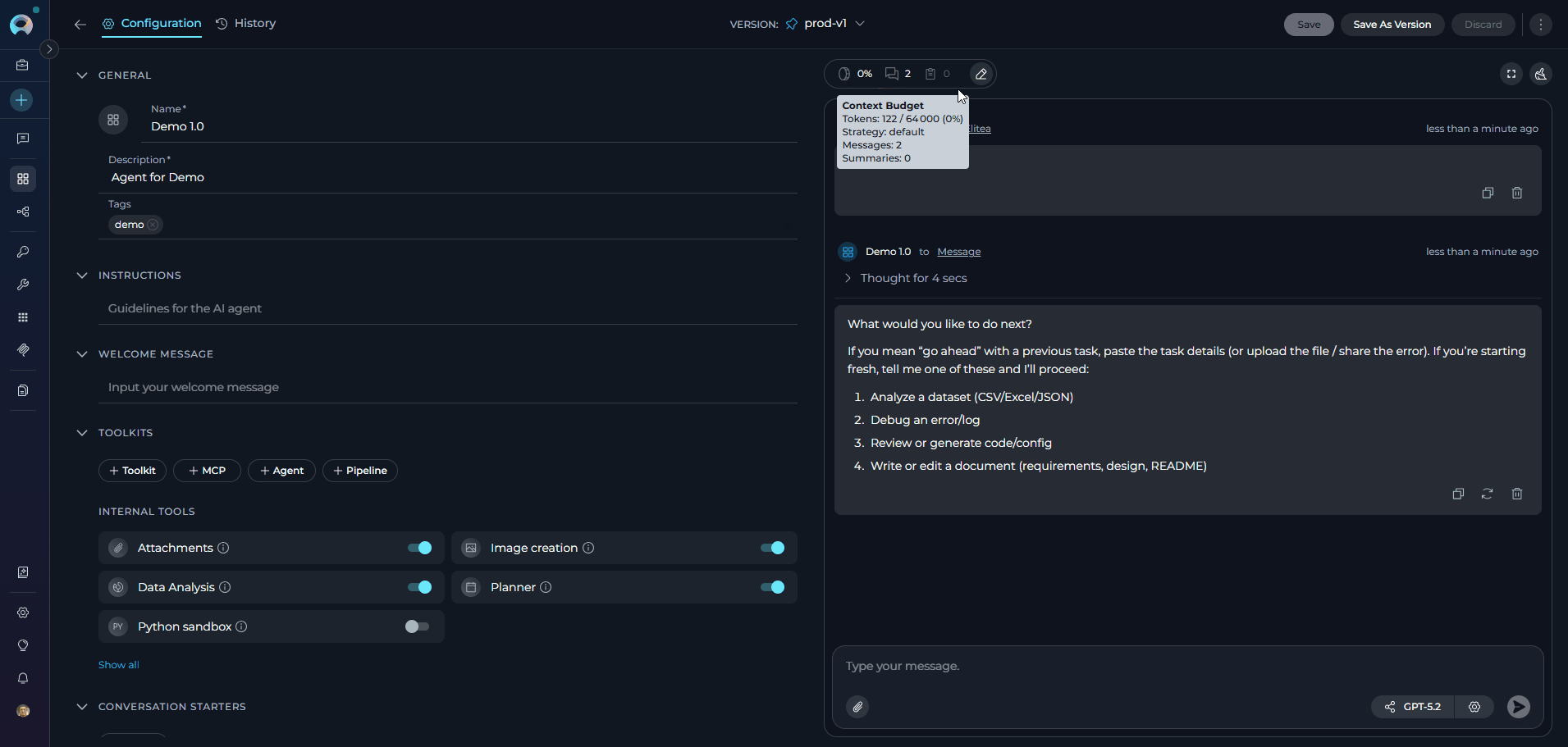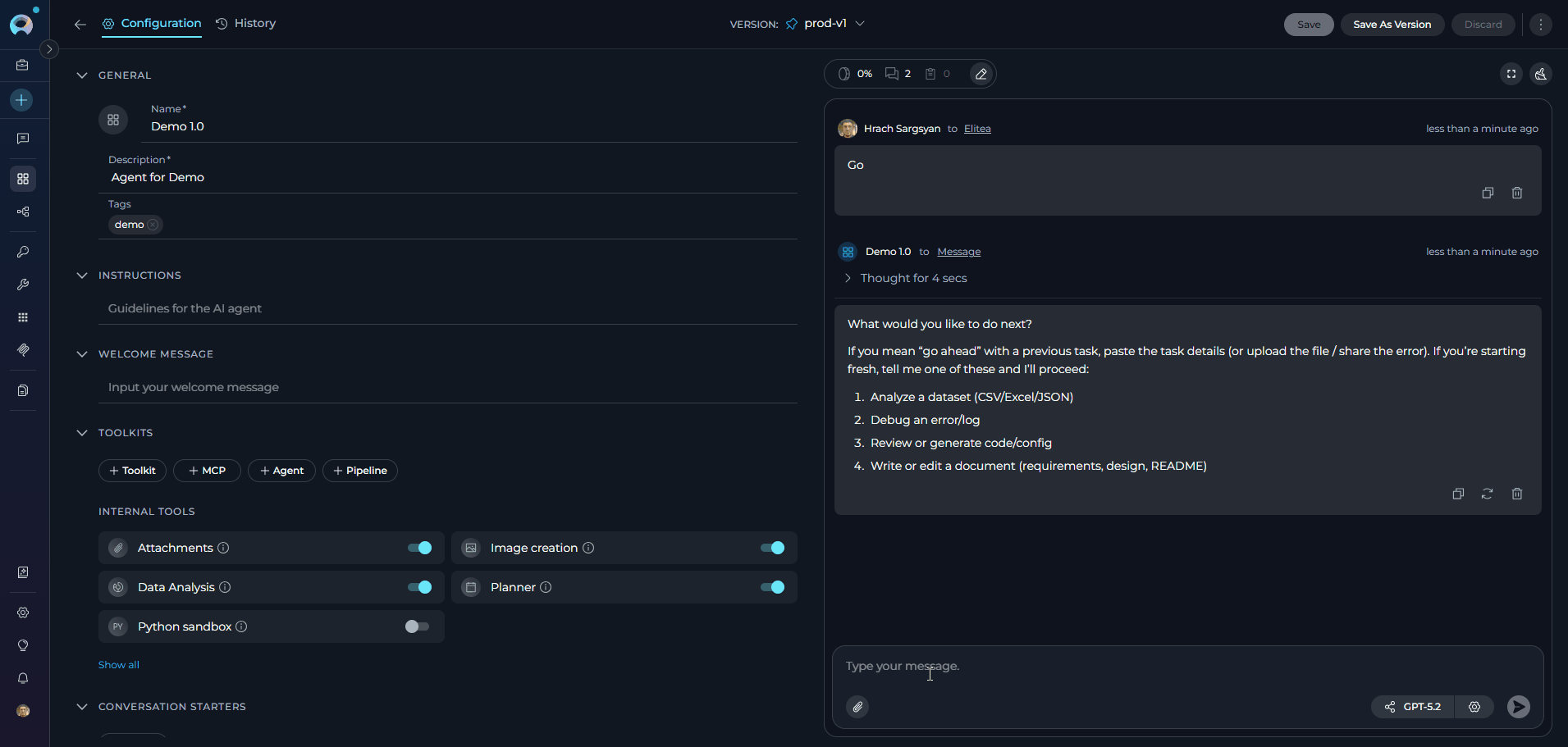
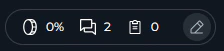
Compact View The compact view adds token usage, message, and summary tracking:
- Token Usage: Current token utilization percentage with a high-usage warning indicator when context is running low
- Messages Count: Total messages in conversation context
- Summaries Count: Number of generated summaries
-
Edit Button: Click to open the full Context Management configuration modal
Conversation
Expanded View The full view displays comprehensive context management details organized in collapsible sections. Click on each section to expand and configure settings. Available Sections:
- Context Strategy & Token Management: Configure token limits and message preservation settings
- Summarization: Enable automatic summarization and configure summary generation parameters
-
User Instructions: Manage system message preservation, default persona, and custom user instructions
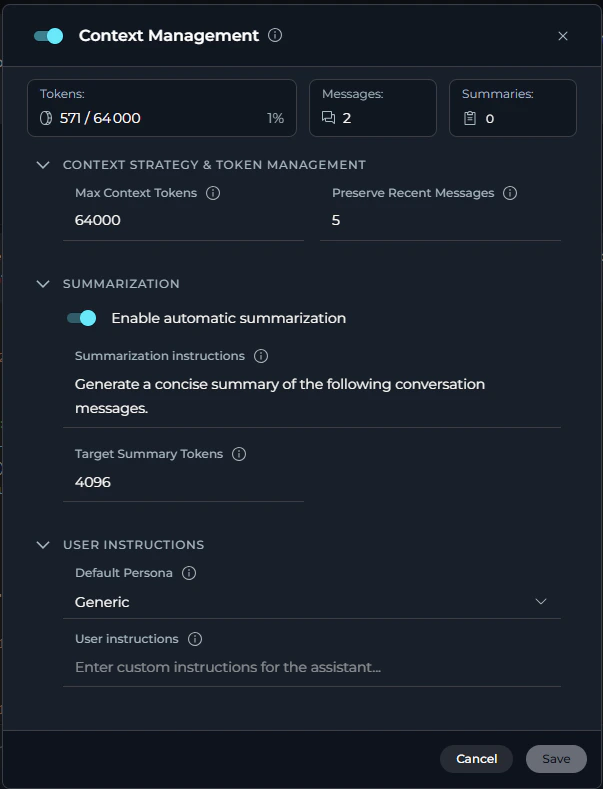
-
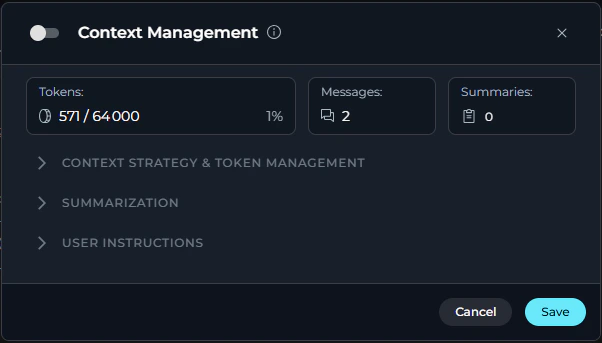
At the top of the expanded view, there is a toggle switch to enable or disable Context Management entirely. When disabled, all automatic context management features (pruning and summarization) are turned off.
How Context Management Works
Automatic Token Tracking The system continuously monitors token consumption:- Message Addition: Every new message added to conversation context
- Token Estimation: Tokens calculated using tiktoken library (with character-based fallback)
- Real-Time Display: Context Budget widget updates immediately
- Threshold Monitoring: System checks if usage is approaching the maximum context token limit
When the model reaches its output token limit before finishing a response, a prompt appears directly in the chat. Click the Continue button to resume and receive the rest of the response. This may occur multiple times for very long outputs.
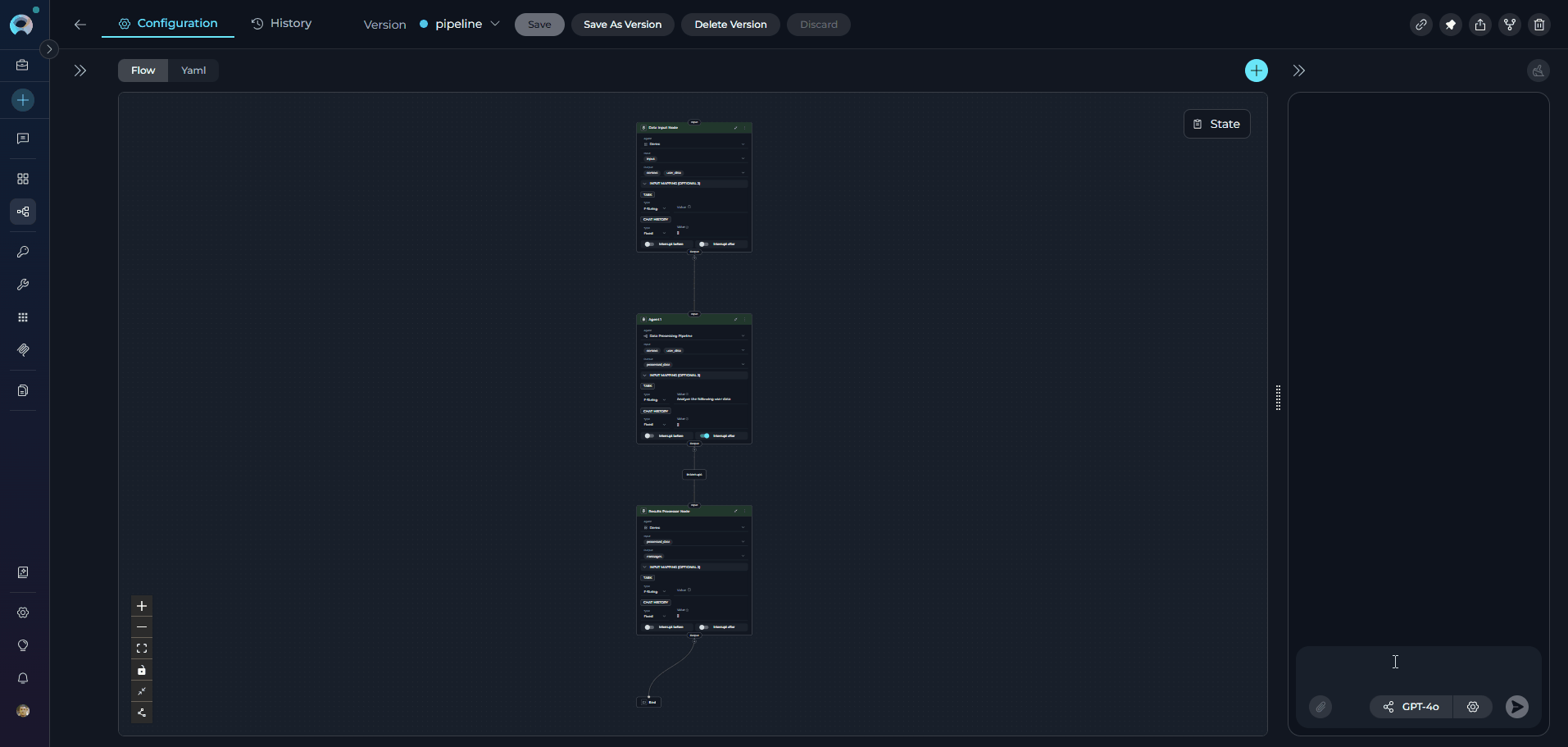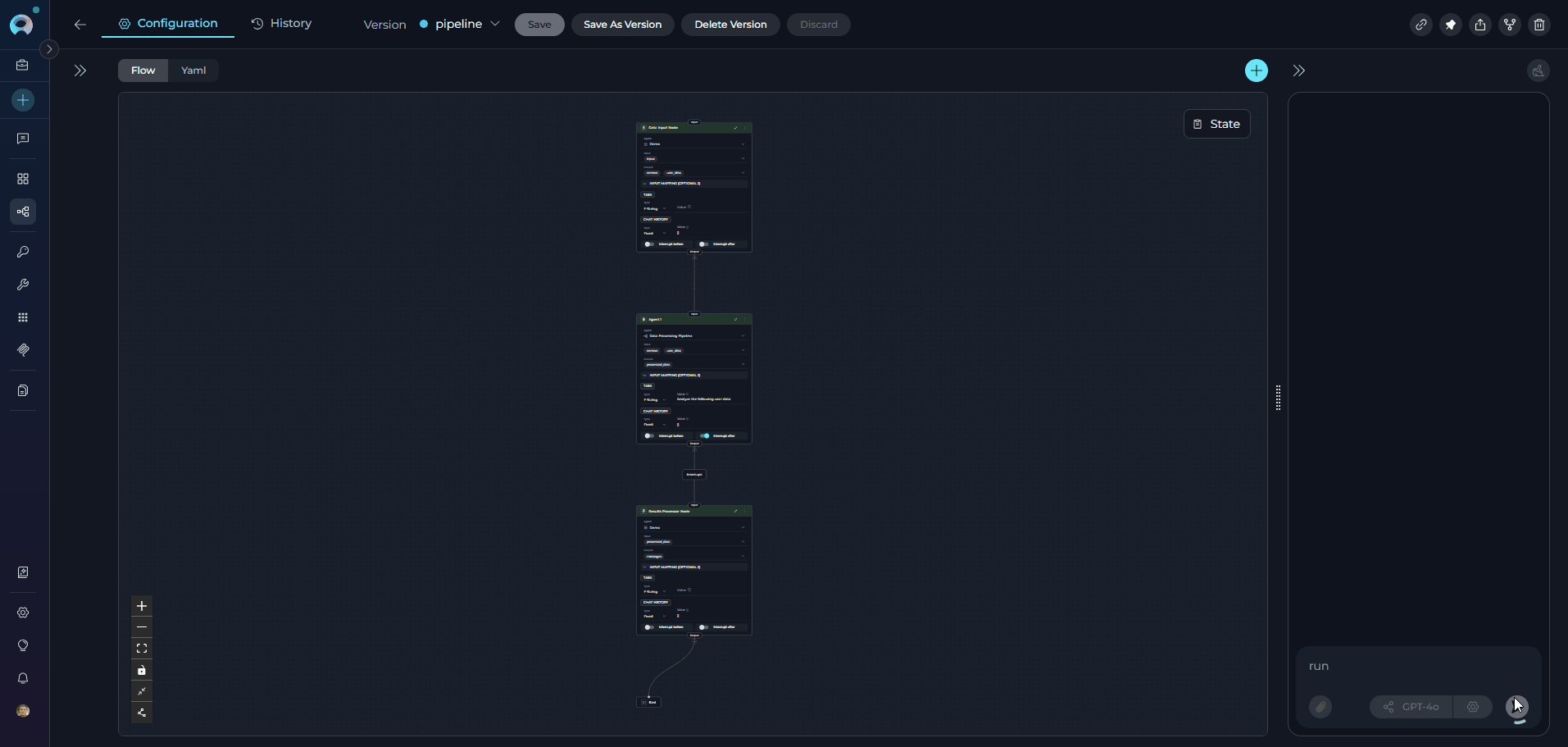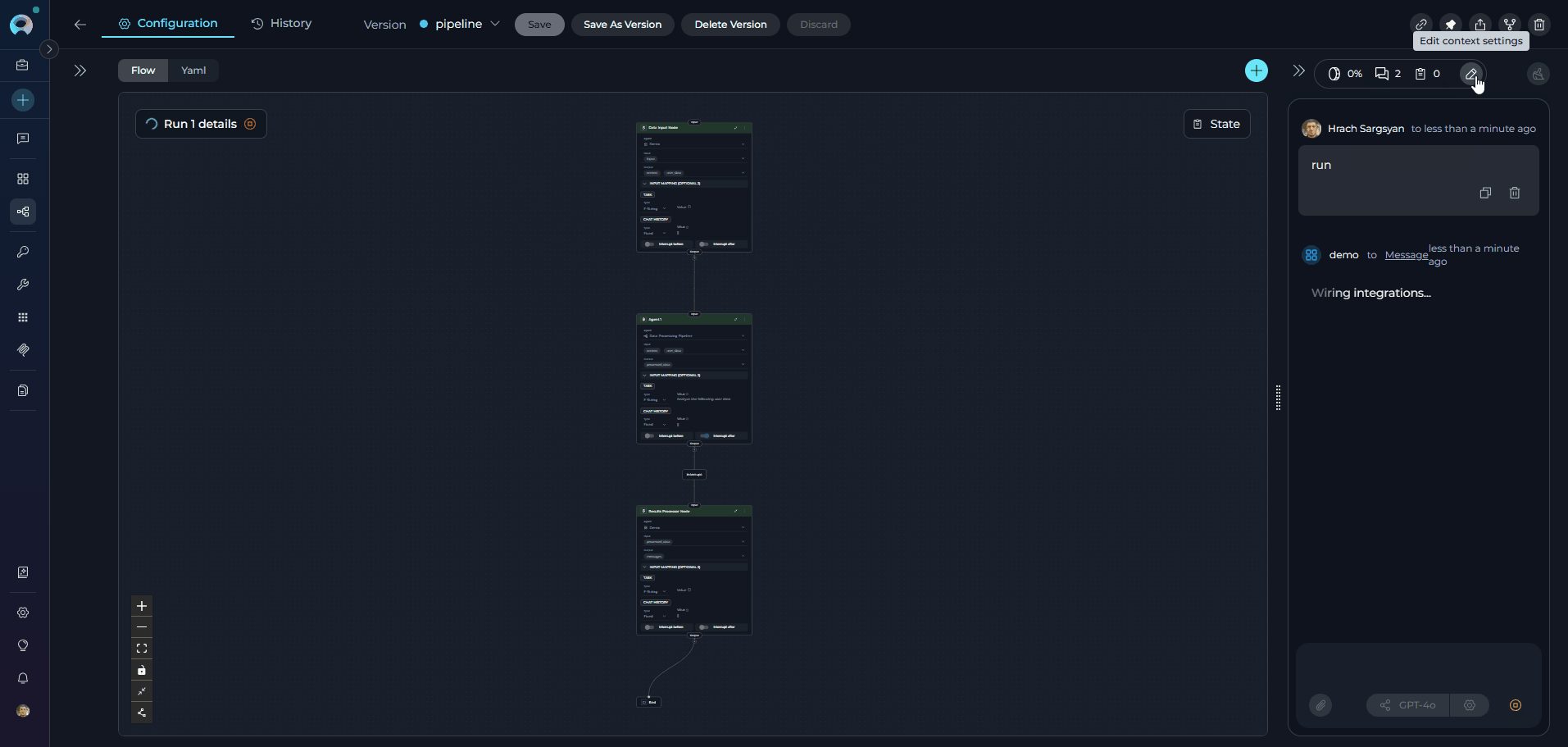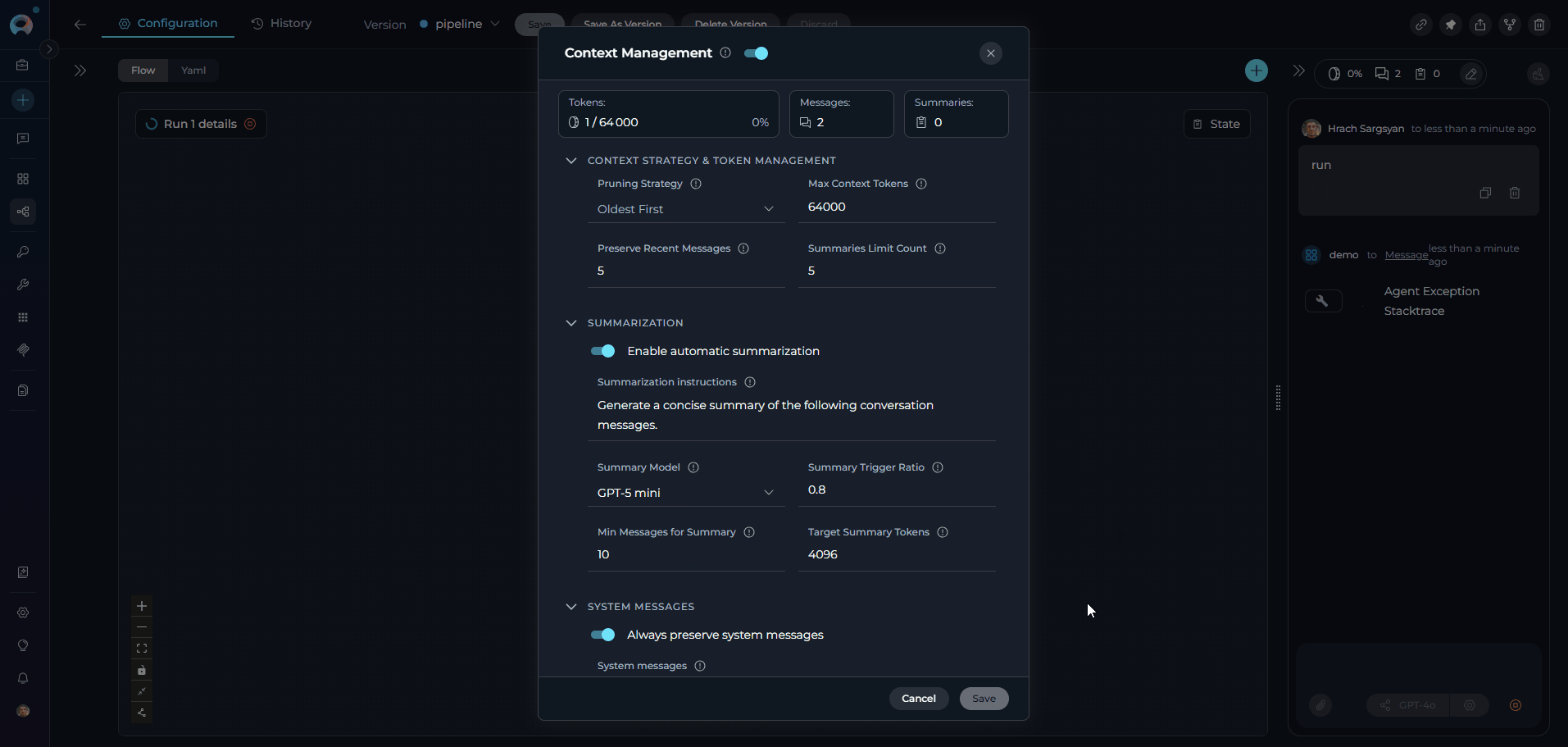
Configuration Parameters
Overview Metrics
-
The expanded view displays three real-time usage metrics:

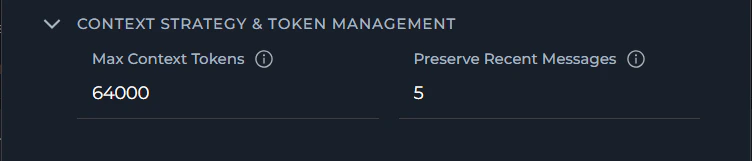
Context Strategy & Token Management
-
Configure token limits and message preservation to control how context is managed:
Summarization
-
Configure automatic summarization to compress older messages and preserve conversation continuity:
 !!! info Target Summary Tokens must always be less than Max Context Tokens. The UI enforces this rule and will prevent saving if the value equals or exceeds Max Context Tokens.
!!! info Target Summary Tokens must always be less than Max Context Tokens. The UI enforces this rule and will prevent saving if the value equals or exceeds Max Context Tokens.
How Summarization Works
- When the context approaches the token limit:
- Summarization Trigger: System detects token usage exceeds trigger ratio (e.g., 100%)
- Message Selection: Identifies messages eligible for summarization (excludes preserved recent messages)
- Summary Generation: LLM generates concise summary of selected messages using the configured Summary Model and Summarization Instructions
- Message Replacement: Original messages replaced with summary in context
- Token Reduction: Context token count reduced while preserving conversation continuity
- Summary Storage: Summary tracked (total summaries limited by summaries_limit_count)
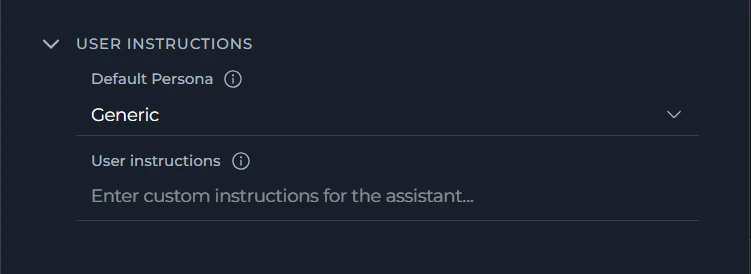
User Instructions
-
Configure system message preservation, default persona, and custom instructions for the assistant:
Usage Scenarios
Long-Running Conversations
Long-Running Conversations
Use Case: Maintain coherent conversations that exceed model token limitsConfiguration:
- Max Context Tokens: 64,000
- Preserve Recent Messages: 10
- User engages in extended conversation with AI assistant
- Context grows naturally as messages are added
- As context grows, older messages are automatically summarized to free up space
- System generates summary of older messages
- Last 10 messages always preserved for immediate context
- Conversation continues seamlessly with reduced token usage
- No manual intervention required
- Important conversation details preserved in summaries
- Recent context always available
- Conversation never “forgets” early important information
Multi-Turn Agent Tasks
Multi-Turn Agent Tasks
Use Case: Agent performing complex tasks requiring multiple interactionsConfiguration:
- Max Context Tokens: 32,000
- Preserve Recent Messages: 5
- Agent starts task with initial instructions
- Multiple tool calls and responses accumulate
- As the context grows, oldest messages are automatically pruned to stay within the token limit
- Last 5 exchanges preserved for immediate task context
- Agent continues task execution without context overflow
- Task execution never interrupted by token limits
- Most recent tool results always accessible
- Efficient token usage for long-running tasks
- Simplified context management for automated workflows
Pipeline Chat Contexts
Pipeline Chat Contexts
Use Case: Pipeline with chat panel interface requiring context preservationConfiguration:
- Max Context Tokens: 16,000
- Preserve Recent Messages: 8
- Pipeline nodes generate output and chat messages
- User interactions add additional context
- Context Budget widget shows real-time usage across pipeline execution
- As the context grows, automatic pruning occurs to maintain token limits
- Recent user messages are preserved per the configured setting
- Pipeline continues with optimized context
- Pipeline execution state preserved
- User can continue interacting without interruption
- Important node outputs retained
- Balanced context across pipeline stages
Best Practices
Monitoring Context UsageRegular Budget Checks
Regular Budget Checks
- Check Context Budget widget periodically during long conversations
- Pay attention to color changes in the percentage bar:
- Green: Safe range, context is within limits
- Yellow: Context is at or beyond the configured limit; the widget also shows the warning “Context usage is high. Consider configuring budget settings.”
- Expand widget to full view for detailed metrics when the bar turns yellow
- Use compact view for quick token usage and message count checks
Understanding Token Consumption
Understanding Token Consumption
- Different message types consume different token amounts:
- System prompts: Variable (often 100-500 tokens)
- User messages: Depends on length (typically 10-200 tokens)
- Assistant responses: Variable (often 100-1000+ tokens)
- Tool calls: Includes function definitions (can be 50-300 tokens each)
- Attachments and images can significantly increase token usage
- Summary messages reduce overall token count while preserving information
Optimizing Conversations
Message Structure
Message Structure
- Keep messages concise when possible to reduce token consumption
- Break long messages into smaller logical chunks
- Avoid unnecessary repetition or verbose phrasing
Preserve Recent Messages Setting
Preserve Recent Messages Setting
- Adjust based on conversation type:
- Quick Q&A: Lower number (3-5 messages)
- Complex discussions: Higher number (10-15 messages)
- Multi-step tasks: Medium number (5-10 messages)
- Remember: Preserved messages are never pruned or summarized
- Higher numbers mean more guaranteed context but less flexibility
Coordinating Target Summary Tokens with Max Context Tokens
Coordinating Target Summary Tokens with Max Context Tokens
- Target Summary Tokens must always be less than Max Context Tokens — the UI enforces this rule and will prevent saving if it is violated
- A good rule of thumb: set Target Summary Tokens to roughly 5–10% of your Max Context Tokens value (e.g., 4,096 Target Summary Tokens with 64,000 Max Context Tokens)
- Very small Target Summary Tokens values produce very short, possibly lossy summaries; very large values leave little room for active conversation context
- Adjust based on how much detail you need preserved in summaries
Troubleshooting
Context Budget Widget Not Visible
Context Budget Widget Not Visible
Symptoms:
- Widget completely missing from the interface
- No context management controls available
- Confirm you’re viewing a supported interface (Chat, Agent, Pipeline)
- Send at least one message — the widget only appears after the first message initiates a conversation
- Check browser console for errors
- Ensure you have sent at least one message to start the conversation
- Refresh the page and try again
- If the issue persists, contact your administrator to check backend service health
Token Count Seems Inaccurate
Token Count Seems Inaccurate
Symptoms:
- Displayed token count doesn’t match expectations
- Percentage bar doesn’t align with message count
- Token counting uses tiktoken library with character-based fallback (~4 chars per token)
- Different message types have different token densities
- System messages, role labels, and formatting add overhead
- Tool calls include function definitions in token count
- Token counts are estimates and may vary slightly from actual LLM processing
- Focus on relative changes (increasing/decreasing) rather than absolute accuracy
- If consistently far off, contact administrator to check token estimation configuration
Summarization Not Occurring
Summarization Not Occurring
Symptoms:
- Summaries count does not increase even as context grows
- Context continues to grow beyond expected limit
- Insufficient messages to summarize (all recent messages preserved)
- LLM model configuration issue
- Backend summarization disabled
- Check expanded view: Compare Messages vs Preserve Recent count
- If Messages ≤ Preserve Recent, summarization cannot occur
- Verify LLM model is properly configured for text generation
- Contact administrator to check backend context management configuration
Messages Disappearing Unexpectedly
Messages Disappearing Unexpectedly
Symptoms:
- Messages from earlier in conversation no longer visible
- Conversation feels disjointed or missing context
- This is expected behavior when pruning occurs
- Messages are removed from context when token limit is approached
- Pruned messages are not deleted, just removed from active context
- Automatic pruning removes oldest messages when the token limit is approached
- Recent messages (per preserve_recent_messages) never disappear
- Increase max_context_tokens to reduce pruning frequency
- Increase preserve_recent_messages to keep more messages
Settings Not Saving — Inline Validation Error
Settings Not Saving — Inline Validation Error
Symptoms:
- Save button remains disabled
- A field shows an inline red error message
- Target Summary Tokens is equal to or greater than Max Context Tokens — the UI validation requires Target Summary Tokens to be strictly less than Max Context Tokens
- Example error shown:
Must be less than Max Context Tokens (64000)
- Open the Summarization accordion in the Context Management settings
- Check the Target Summary Tokens value
- Reduce it to a value less than Max Context Tokens (e.g., set to 4,096 when Max Context Tokens is 64,000)
- The Save button will re-enable once all validation errors are cleared
Settings Not Saving — Toast Error After Submit
Settings Not Saving — Toast Error After Submit
Symptoms:
- A toast notification appears with the message: “Failed to update context strategy”
- Settings appear to revert to previous values
- Network connectivity issue
- API or backend service error
- Session has expired
- Check your network connection and retry
- Refresh the page and attempt to save again
- If the problem persists, contact your administrator to check backend service health
Performance Issues
Performance Issues
Symptoms:
- Slow message sending or response times
- UI lag when interacting with Context Budget widget
- Browser becomes unresponsive
- Very high max_context_tokens causing expensive operations
- Excessive message count in conversation
- Frequent summarization operations
- Browser memory limitations
- Reduce max_context_tokens:
- Lower values mean less context to process
- Typical range: 8,000 - 32,000 for optimal performance
- Start new conversation:
- Very long conversations can accumulate state
- Consider starting fresh for new topics
- Check browser resources:
- Close unnecessary tabs
- Ensure browser is up to date
- Clear browser cache if needed
- Contact administrator:
- May need to adjust backend processing limits
- Could configure more aggressive pruning
Support Contact
If you encounter issues not covered in this guide or need additional assistance with context management, please refer to Contact Support for detailed information on how to reach the ELITEA Support Team.- Chat Functionality - General chat features and usage
- Agent Configuration - Setting up agents with context management
- Pipeline Configuration - Configuring pipelines with context support